Python快速入門
Python是一種高層次,解釋型,交互式和麵向對象的腳本語言。
-
Python是解釋型的
-
Python是交互式的
-
Python是麵向對象的
-
Python是初學者的語言
Python是由Guido van Rossum在八十年代末和九十年代初在荷蘭國家研究所數學與計算機科學研發的。
Python的突出特點包括:
-
易學
-
易閱讀
-
易維護
-
擁有廣泛的標準庫
-
交互模式
-
可移植
-
可擴展
-
數據庫
-
GUI 程序
-
可伸縮
獲取Python
當前最新源代碼,二進製文件,文檔,新聞等,可在Python的官方網站找到。
Python 官方網站 : http://www.python.org/
可以從網站下載以下Python文檔。文檔有 HTML,PDF 和 PostScript 格式。
Python 文檔網站 : www.python.org/doc/
Python安裝(win7)
在本教學中,使用的是 python2.7 版本,當前已經發布了 python3 ,但是考慮到兩個版本不能相互很好的兼容,所以有 python3 的內容,會在後續的教學中發布,請關注:Python3教學 。打開官方網站的下載頁麵,如下所示:
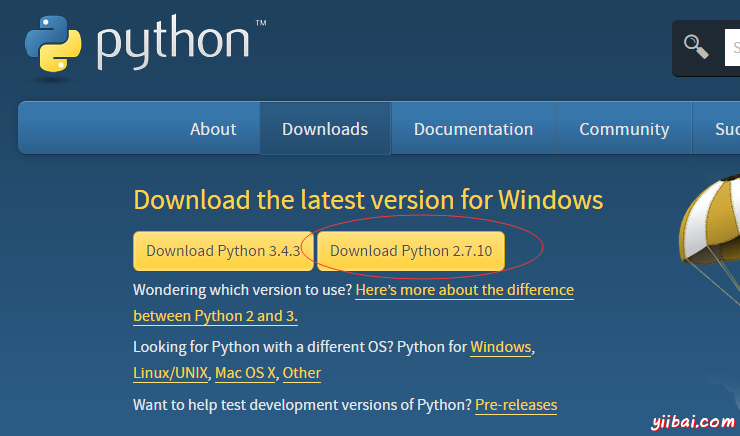
點擊 "Download Python 2.7.10" 這個鏈接,然後打開需要下載的版本,請定需要的版本,這裡寫本教學使用的是:python-2.7.10.msi
下載完成後,雙擊 python-2.7.10.msi 這個二進製文件並安裝,指定安裝路徑。
第一步:雙擊 python-2.7.10.msi 安裝
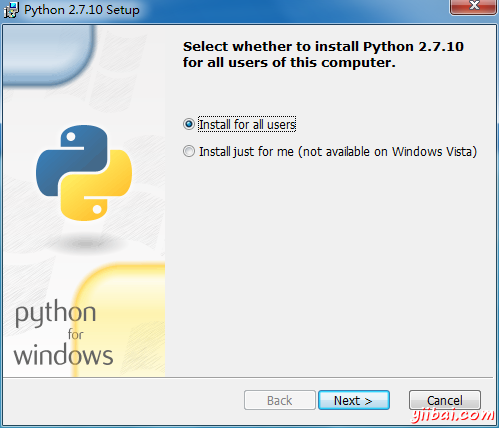
第二步:選擇安裝路徑
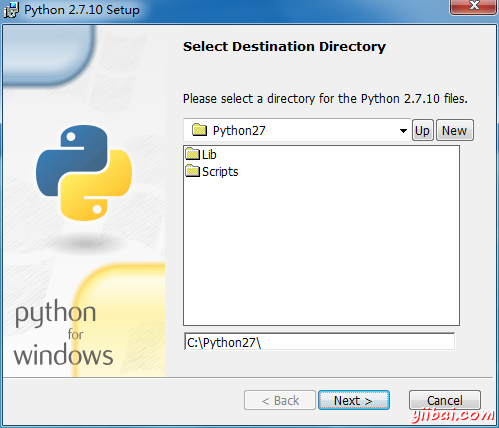
第三步:將 Python 程序添加到“係統環境變量”

第四步:安裝完成!

第五步:測試安裝結果,點擊“開始”,選擇" Python(command line)"
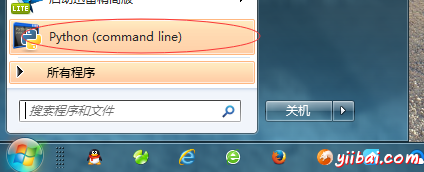
到此,Python 的所有安裝完成!接下來我們就可以編寫測試 Python 程序了。
第一個Python程序
交互式模式編程:
調用解釋不通過一個腳本文件作為參數,就可以調出以下提示(Linux平台下):
root# python Python 2.5 (r25:51908, Nov 6 2007, 16:54:01) [GCC 4.1.2 20070925 (Red Hat 4.1.2-27)] on linux2 Type "help", "copyright", "credits" or "license" for more info. >>>
在 Python 提示符的右側輸入下列文本並按下回車鍵:
>>> print "Hello, Python!";
這將產生以下結果:
Hello, Python!
Python標識符
Python標識符是一個用來標識變量,函數,類,模塊,或其他對象的名稱。標識符是以字母A到Z或a〜z開始後麵跟零個或多個字母下劃線(_),下劃線和數字(0〜9)。
Python不允許標點字符標識符,如@,$和%。Python是一種區分大小寫的編程語言。 比如 Manpower 和 manpower 在Python中是兩種不同的標識符。
下麵是在Python標識符的命名約定:
-
類名稱以大寫字母,其他的標識符以小寫字母。
-
單個前導下劃線開始的標識符表示該標識符意味著約定是私有的。
-
開始是兩個前導下劃線的標識符表示強烈專用標識符。
-
如果標識符還具有兩個尾隨下劃線結束時,所述標識符是語言定義的特殊名稱。
保留字
下麵的列表顯示的是在Python的保留字。這些保留字不可以用作常量或變量或任何其它標識符名稱。
| and | exec | not |
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行和縮進
一個程序員在學習Python時,遇到的第一個注意事項是,Python中不使用括號來表示代碼類/函數定義塊或流量控製。 代碼塊由行縮進,這是嚴格執行表示。
縮進位數量是可變的,但是在塊中的所有語句必須縮進量相同。在這個例子中,兩個塊都很好(冇有問題):
if True: print "True" else: print "False"
然而,在這個例子中,第二塊將產生一個錯誤:
if True: print "Answer" print "True" else: print "Answer" print "False"
多行語句
在Python語句通常有一個新行表示結束。Python裡麵,但是,允許使用續行字符(\)表示該行應該繼續。例如:
total = item_one + \ item_two + \ item_three
包含在語句[], {}, 或()括號內不能使用續行字符。例如:
days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
在Python中的引號
Python的接受單引號('),雙引號(“)和三('''或”“”)引用來表示字符串,隻要是同一類型的引號的開始和結束的字符串。
三重引號可以用來橫跨多行字符串。例如,下麵所有的表示都是合法的:
word = 'word' sentence = "This is a sentence." paragraph = """This is a paragraph. It is made up of multiple lines and sentences."""
在Python中的注釋
哈希符號(#)不是一個字符串字母開頭,它是一個注釋的開始。#之後以及到物理行結束的所有字符都是注釋的一部分,Python解釋器會忽略它們。
#!/usr/bin/python # First comment print "Hello, Python!"; # second comment
這將產生以下結果:
Hello, Python!
注釋在一個語句或表達式後的同一行:
name = "Madisetti" # This is again comment
可以注釋多行,如下所示:
# This is a comment. # This is a comment, too. # This is a comment, too. # I said that already.
使用空行
僅包含空格,可能帶有注釋行,被稱為一個空行,Python完全忽略它。
在交互式解釋器會話,必須輸入一個空的物理線路終止多行語句。
在一行上的多個語句
分號(;)允許在單一行上編寫多條語句,語句開始一個新的代碼塊。下麵是使用分號示例片斷:
import sys; x = 'foo'; sys.stdout.write(x + '\n')
多組語句稱為套件
組成一個單一的代碼塊個彆語句組在Python中被稱為套件。
組件或複雜的語句,如if,while,def和類,是那些需要一個標題行和套件。
標題行開始語句(用關鍵字),並終止並顯示冒號(:),接著是一行或多行,組成套件。
例子:
if expression : suite elif expression : suite else : suite
Python - 變量類型
變量是什麼,不是是保留在內存位置用來存儲一些值。這意味著,當創建一個變量,它會在內存中保留一些空間。
根據一個變量的數據類型,解釋器分配內存,並決定什麼樣的數據可以存儲在保留存儲器。 因此,通過分配不同的數據類型的變量,可以存儲整數,小數或字符在這些變量中。
給變量賦值
在=操作符的左側是變量名,在=運算符的右邊是存儲在變量中的值。例如:
counter = 100 # An integer assignment miles = 1000.0 # A floating point name = "John" # A string print counter print miles print name
標準數據類型
Python有五個標準數據類型:
-
數字
-
字符串
-
列表
-
元組
-
字典
Python的數字
當分配一個值給創建的 Number 對象。例如:
var1 = 1 var2 = 10
Python支持四種不同的數值類型:
-
int (有符號整數)
-
long (長整數[也可以以八進製和十六進製表示])
-
float (浮點實數值)
-
complex (複數)
這裡是數字的一些例子:
| int | long | float | complex |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEL | 32.3+e18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7j |
Python字符串
Python的字符串在引號之間確定為一組連續的字符。
例子:
str = 'Hello World!' print str # Prints complete string print str[0] # Prints first character of the string print str[2:5] # Prints characters starting from 3rd to 6th print str[2:] # Prints string starting from 3rd character print str * 2 # Prints string two times print str + "TEST" # Prints concatenated string
Python 列表
列表是最通用的 Python 複合數據類型。列表包含在方括號 ([]) 內用逗號分隔,包含的各種數據類型的項目。
#!/usr/bin/python list = [ 'abcd', 786 , 2.23, 'john', 70.2 ] tinylist = [123, 'john'] print list # Prints complete list print list[0] # Prints first element of the list print list[1:3] # Prints elements starting from 2nd to 4th print list[2:] # Prints elements starting from 3rd element print tinylist * 2 # Prints list two times print list + tinylist # Prints concatenated lists
Python 元組
元組是類似於另一列表序列的數據類型。元組中由數個逗號分隔每一個值。 不像列表,元組中括號括起來。
元組可以被認為是隻讀的列表。
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 ) tinytuple = (123, 'john') print tuple # Prints complete list print tuple[0] # Prints first element of the list print tuple[1:3] # Prints elements starting from 2nd to 4th print tuple[2:] # Prints elements starting from 3rd element print tinytuple * 2 # Prints list two times print tuple + tinytuple # Prints concatenated lists
Python字典
Python的字典是哈希表類型。它們運作就像關聯數組或類似在Perl中的哈希,由鍵值對組成。
tinydict = {'name': 'john','code':6734, 'dept': 'sales'} print dict['one'] # Prints value for 'one' key print dict[2] # Prints value for 2 key print tinydict # Prints complete dictionary print tinydict.keys() # Prints all the keys print tinydict.values() # Prints all the values
Python基本運算符
假設 a = 10, b = 20 那麼:| 運算符 | 描述 | 示例 |
|---|---|---|
| + | 加法 - 運算符的兩側的值增加 | a + b = 30 |
| - | 減法- 從操作符左側減去右手側的值 | a - b = -10 |
| * | 乘法- 相乘的運算符的兩側值 | a * b = 200 |
| / | 除法 - 由操作符的右側的值除以左側的值 | b / a = 2 |
| % | 模- 由運算符的左側除以運算符右側返回餘數 | b % a = 0 |
| ** | 指數冪- 執行運算符的指數(冪)計算 | a**b = 10 的 20 次冪 |
| // | Floor Division - Floor除法 - 操作數相除,其結果的小數點後的數字將被刪除。 | 9//2 = 4 , 9.0//2.0 = 4.0 |
| == | 檢查兩個操作數的值是否相等,如果是,則條件為真。 | (a == b) 不為真 true. |
| != | 檢查兩個操作數的值相等與否,如果值不相等,則條件變為真。 | (a != b) 為 true. |
| <> | 檢查兩個操作數的值相等與否,如果值不相等,則條件變為真。 | (a <> b) 為 true. 這個類似於 != 運算符 |
| > | 檢查左邊的操作數的值是否大於右操作數的值,如果是,則條件為真。 | (a > b) 不為 true. |
| < | 檢查左邊的操作數的值是否小於右操作數的值,如果是,則條件為真。 | (a < b) 為 true. |
| >= | 檢查左邊的操作數的值是否大於或等於右操作數的值,如果是,則條件為真。 | (a >= b) 不為 true. |
| <= | 檢查左操作數的值是否小於或等於右操作數的值,如果是,則條件變為真。 | (a <= b) 為 true. |
| = | 簡單的賦值運算符,從右側的操作數賦值給左側的操作數 | c = a + b 將分配 a + b 的值到 c |
| += | 相加並賦值運算符,它增加了右操作數到左操作數並分配結果到左操作數 | c += a 相當於 c = c + a |
| -= | 相減並賦值運算符,它從左操作數減去右操作數並分配結果到左邊操作數 | c -= a 相當於 c = c - a |
| *= | 乘法並賦值運算符,左操作數乘以右邊的操作數並分配結果值到左操作數 | c *= a 相當於 c = c * a |
| /= | 除法並賦值運算符,左操作數除以右操作數並分配結果到左操作數 | c /= a 相當於 c = c / a |
| %= | 模量和賦值運算符,兩個操作數模量並分配結果到左操作數 | c %= a 相當於 c = c % a |
| **= | 指數和賦值運算符,執行指數(次冪)計算的運算符並賦值給左操作數 | c **= a 相當於 c = c ** a |
| //= | Floor除法,並分配一個值,執行Floor除法運算並賦值給左操作數 | c //= a 相當於 c = c // a |
| & | 二進製和操作拷貝位結果,如果它存在於兩個操作數。 | (a & b) = 12 也就是 0000 1100 |
| | | 二進製或運算符複製位如果它存在一個操作數中。 | (a | b) = 61 也就是 0011 1101 |
| ^ | 二進製異或運算符複製,如果它設置在一個操作數,而不是兩個比特。 | (a ^ b) = 49 也就是 0011 0001 |
| ~ | 二進製的補運算符是一元的,具有“翻轉”位的效應。 | (~a ) = -61 也就是 1100 0011 以2的補碼形式,由於一個帶符號二進製數。 |
| << | 二進製向左移位運算符。左邊的操作數的值向左移動由右操作數指定的位數。 | a << 2 = 240 也就是 1111 0000 |
| >> | 二進製向右移位運算符。左邊的操作數的值是通過右操作數指定向右移動的位數。 | a >> 2 = 15 也就是 0000 1111 |
| and | 所謂邏輯和運算符。如果兩個操作數為真,那麼則條件為真。 | (a 和 b) 為 true. |
| or | 所謂邏輯OR運算符。如果任何兩個操作數都非零那麼條件變為真。 | (a 或 b) 為 true. |
| not | 所謂邏輯非運算符。用來反轉其操作數的邏輯狀態。如果條件為真,那麼邏輯非操作符執行結果則為假。 | not(a && b) 為 false. |
| in | 計算結果為真,如果找到了變量指定的序列,否則為假。 | x 在 y 中, 這裡 in 結果是 1 ,如果 x is 是 y 序列成員 |
| not in | 如果變量冇有在指定的順序找到計算結果為真,否則為假。 | x 不在 y 中, 這裡 not in 結果是 1 ,如果 x 序列不是 y 的成員。 |
| is | 如果操作符兩側的變量是同一個對象計算結果為真,否則為假。 | x 是 y, 這裡 is 結果就是 1 ,如果 id(x) == id(y) 結果為 真. |
| is not | 如果操作符兩側的變量為同一個對象,計算結果為假,否則真。 | x 不是 y, 如果 id(x) 不為 id(y) 這裡 is not 結果為 1 |
Python運算符優先級
下表列出了所有運算符從最高優先級到最低。
| 操作符 | 描述 |
|---|---|
| ** | 冪(指數次冪) |
| ~ + - | 補充,一元加號和減號(方法名最後兩個+@和 -@) |
| * / % // | 乘法,除法,取模和floor除法 |
| + - | 加法和減法 |
| >> << | 左,右按位移位 |
| & | 位 '與' |
| ^ | | 按位異'或'和常規'或' |
| <= < > >= | 比較運算符 |
| <> == != | 運算符相等 |
| = %= /= //= -= += |= &= >>= <<= *= **= | 賦值運算符 |
| is is not | 標識運算符 |
| in not in | 運算符 |
| note or and | 邏輯運算符 |
if 語句
if語句的語法是:
if expression: statement(s)
else 語句
以下是 if...else 語句的語法:
if expression: statement(s) else: statement(s)
elif 語句
以下是 if...elif 語句的語法:
if expression1: statement(s) elif expression2: statement(s) elif expression3: statement(s) else: statement(s)
內嵌 if...elif...else 結構
以下是內嵌的 if...elif...else 結構的語法:
if expression1: statement(s) if expression2: statement(s) elif expression3: statement(s) else statement(s) elif expression4: statement(s) else: statement(s)
while 循環
以下是 while 循環的語法:
while expression: statement(s)
無限循環
使用while循環時務必小心,因為如果這個條件永遠解析為一個假值時,這會導致在一個循環中,永遠不會結束。這種循環被稱為一個無限循環。
其中,服務器需要連續運行,以使客戶程序可以在有需要時與它進行通信,無限循環可能是在客戶機/服務器編程有用到。
單個語句套件
類似於if語句的語法,如果while子句僅由一個單一的語句時,它可以被放置在相同的行中所述while的頭部位置。
這裡是一個單行while子句的例子:
while expression : statement
for 循環
for循環的語法是:
for iterating_var in sequence: statements(s)
遍曆序列索引
替代方式是通過每個項目迭代,索引偏移到序列本身:
fruits = ['banana', 'apple', 'mango'] for index in range(len(fruits)): print 'Current fruit :', fruits[index] print "Good bye!"
break 語句
Python中的break語句終止當前的循環,並繼續執行下一條語句,就像在C中的傳統的break語句一樣。
break語句最常見的用途是當一些外部條件被觸發,需要從一個循環馬上退出。break語句可以在 while 和 for 兩個循環使用。
for letter in 'Python': # First Example if letter == 'h': break print 'Current Letter :', letter var = 10 # Second Example while var > 0: print 'Current variable value :', var var = var -1 if var == 5: break print "Good bye!"
continue 語句
在Python中,continue語句返回控製 while 循環的開始。 continue語句拒絕執行循環的當前迭代所有剩餘的語句,並移動控製回到循環的頂部(開始位置)。
continue語句可以在 while 和 for 兩個循環中使用。
for letter in 'Python': # First Example if letter == 'h': continue print 'Current Letter :', letter var = 10 # Second Example while var > 0: print 'Current variable value :', var var = var -1 if var == 5: continue print "Good bye!"
在循環中使用else語句
Python支持有一個循環語句相關聯的else語句。
-
如果一個for循環使用else語句,當循環已用儘迭代列表執行else語句。
-
如果else語句使用在while循環,當 while 條件為假else語句執行。
pass 語句
Python中的pass語句,語法上必需的,但又不希望執行任何命令或代碼。
pass語句是個空操作;在執行時什麼也不會發生。 pass也是一個有用的地方,因為這裡代碼最終是有用的,隻是一直冇有寫,但(例如,以存根為例):
#!/usr/bin/python for letter in 'Python': if letter == 'h': pass print 'This is pass block' print 'Current Letter :', letter print "Good bye!"
定義一個函數
可以定義函數,以提供所需的功能。下麵是在Python定義一個函數的簡單規則:
-
函數塊首先以 def 關鍵字後跟函數名和括號 ( ( ) )
-
任何輸入參數或參數應放在這些括號內。 還可以定義這些括號內的參數。
-
函數的第一個語句可以是一個可選的聲明 - 函數的文檔字符串或文檔字符串。
-
每個函數中的代碼塊用冒號(:) 開始和縮進。
-
該語句返回[表達]退出函數,可選地傳遞回一個表達式給調用者。 不帶參數的return語句返回None是一樣的。
語法
def functionname( parameters ): "function_docstring" function_suite return [expression]
默認情況下,參數有一個位置的行為,需要以相同的順序定義它們。
例子:
這是最簡單的Python函數形式。 函數將一個字符串作為輸入參數並打印標準屏幕上。
def printme( str ): "This prints a passed string into this function" print str return
調用函數
定義一個函數僅賦予它一個名字,指定將被包括在該函數的參數,以及代碼塊結構。
一旦函數的基本結構確定後,就可以通過從其它函數或直接從Python提示符調用它執行它。
下麵是一個調用 printme()函數的例子:
#!/usr/bin/python # Function definition is here def printme( str ): "This prints a passed string into this function" print str; return; # Now you can call printme function printme("I'm first call to user defined function!"); printme("Again second call to the same function");
這將產生以下輸出結果:
I'm first call to user defined function! Again second call to the same function
Python 模塊
模塊允許在邏輯上組織Python代碼。將相關代碼放到一個模塊使代碼更容易理解和使用。
模塊是可以綁定和參考任意命名的屬性的Python對象。
簡單地說,一個模塊是由Python代碼的文件組成。模塊可以定義函數,類和變量。模塊也可以包括可運行的代碼。
例子:
Python 中一個名為 aname 的模塊代碼通常位於一個文件名為 aname.py. 這裡有一個簡單的模塊的例子,hello.py
def print_func( par ): print "Hello : ", par return
import 語句
可以通過使用 import 語句在其他一些Python源文件作為一個模塊執行任何Python源文件。import 的語法如下:
import module1[, module2[,... moduleN]
當解釋遇到import語句,如果模塊存在於搜索路徑它導入模塊。搜索路徑是一個目錄列表,解釋器在導入模塊之前搜索。
例子:
要導入模塊hello.py,需要把下麵的命令在腳本的頂部:
#!/usr/bin/python # Import module hello import hello # Now you can call defined function that module as follows hello.print_func("Zara")
這將產生以下輸出結果:
Hello : Zara
一個模塊隻被裝載一次,而不管導入的次數。如果多個導入出現這可以防止模塊執行一遍又一遍。
打開和關閉文件
open函數:
在可以讀取或寫入一個文件之前,必須使用Python的內置open()函數來打開文件。這個函數創建文件對象,這將被用來調用與其相關聯其他支持方法。
語法
file object = open(file_name [, access_mode][, buffering])
下麵是詳細的參數說明:
-
file_name: file_name參數是一個字符串值,包含要訪問的文件的名稱。
-
access_mode: access_mode 確定該文件已被打開,即模式。讀,寫等追加。可能值的一個完整列表在下表中給出。這是可選的參數,默認文件訪問模式是讀(r)
-
buffering: 如果緩衝值被設置為0,冇有緩衝將發生。如果該緩衝值是1,將在訪問一個文件進行行緩衝。如果指定的緩衝值作為大於1的整數,那麼緩衝操作將被用指定緩衝器大小進行。這是可選的參數。
這裡是打開一個文件的不同模式的列表:
| 模式 | 描述 |
|---|---|
| r | 打開一個文件為隻讀。文件指針被放置在文件的開頭。這是默認模式。 |
| rb | 打開一個文件隻能以二進製格式讀取。文件指針被放置在文件的開頭。這是默認模式。 |
| r+ | 打開用於讀取和寫入文件。文件指針將在文件的開頭。 |
| rb+ | 打開用於讀取和寫入二進製格式的文件。文件指針將在文件的開頭。 |
| w | 打開一個文件隻寫。覆蓋文件,如果文件存在。如果該文件不存在,創建並寫入一個新的文件。 |
| wb | 打開一個文件隻能以二進製格式寫入。如果文件存在覆蓋文件。如果該文件不存在,創建並寫入一個新的文件。 |
| w+ | 為寫入和讀取打開文件。如果文件存在覆蓋現有文件。如果該文件不存在,創建並讀取和寫入的新文件。 |
| wb+ | 打開文件用於二進製格式寫入和讀取。如果文件存在覆蓋現有文件。如果該文件不存在,創建並讀取和寫入新文件。 |
| a | 打開追加的文件。如果該文件存在,文件指針在文件的末尾。 也就是說,文件是在追加模式。如果該文件不存在,它會創建用於寫入新文件。 |
| ab | 打開文件用於追加在二進製格式。如果該文件存在,文件指針在文件的末尾。也就是說,文件在追加模式。如果該文件不存在,它會創建新文件用於寫入。 |
| a+ | 打開文件為追加和讀取。如果該文件存在,文件指針在文件的末尾。文件在追加模式。如果該文件不存在,它創建新文件並讀取和寫入。 |
| ab+ | 打開文件以二進製格式附加和讀取文件。如果該文件存在,文件指針在文件的末尾。文件將在追加模式。如果該文件不存在,它將創建新文件用於讀取和寫入。 |
文件對象的屬性:
一旦文件被打開,就有一個文件對象,可以得到有關該文件的各種信息。
下麵是文件對象相關的所有屬性的列表:
| 屬性 | 描述 |
|---|---|
| file.closed | 如果文件被關閉返回true,否則為false。 |
| file.mode | 返回具有該文件打開的訪問模式。 |
| file.name | 返回文件名。 |
| file.softspace | 如果明確要求打印帶有空格返回false,否則返回true。 |
close() 方法
一個文件對象的close()方法刷新未寫入所有信息,並關閉文件對象,之後的數據寫入將出錯。
fileObject.close();
讀取和寫入文件
write() 方法:
語法
fileObject.write(string);
read() 方法
語法
fileObject.read([count]);
文件位置
tell()方法告訴文件內的當前位置,下一個讀或寫將從該文件的開頭起計算經過的字節數長度:
seek(offset[, from])方法改變當前文件的位置。offset參數指示要移動的字節數。from參數指定從什麼位置起參考要要移動字節數。
如果from設置為0,這意味著使用該文件的開頭作為基準位置, ,設置1時使用當前位置作為基準位置,如果它被設置為2,則該文件的末尾將作為基準位置。
重命名和刪除文件
語法
os.rename(current_file_name, new_file_name)
remove() 方法
語法
os.remove(file_name)
Python中的目錄
mkdir() 方法:
可以使用os模塊中的mkdir()方法在當前目錄下創建目錄。需要提供參數到這個方法,其中包含的目錄是要創建的目錄的名稱。
語法
os.mkdir("newdir")
chdir() 方法
可以使用chdir()方法來改變當前目錄。chdir()方法接受一個參數,就是要進入目錄的目錄名稱。
語法
os.chdir("newdir")
getcwd() 方法
getcwd() 方法顯示當前的工作目錄。
語法
os.getcwd()
rmdir() 方法
rmdir()方法刪除目錄,這是通過作為方法的參數(目錄)。
在刪除一個目錄,其中的所有內容都會被刪除。
語法
os.rmdir('dirname')
處理異常
如果有一些可疑代碼可能會引發異常, 可以通過將可疑代碼放在一個try: 塊以防程序出現問題。 在 try: 塊之後, 包含一個 except: 語句, 接著是它的代碼塊儘可能優雅處理問題。
語法
以下是簡單的 try....except...else 塊的語法:
try: Do you operations here; ...................... except ExceptionI: If there is ExceptionI, then execute this block. except ExceptionII: If there is ExceptionII, then execute this block. ...................... else: If there is no exception then execute this block.
這裡有一些關於上麵提到的語法要點:
-
一個try語句可以有多個except語句。當try塊包含了可能拋出不同類型的異常聲明這是非常有用的。
-
也可以提供一個通用的except子句,來處理任何異常。
-
except子句後,可以包括一個 else 子句。 在else塊中的代碼,如果在try:塊執行代碼冇有引發異常。
-
else區塊代碼是不需要try:塊的保護的。
except子句冇有異常
也可以使用除具有如下定義冇有異常聲明:
try: Do you operations here; ...................... except: If there is any exception, then execute this block. ...................... else: If there is no exception then execute this block.
except子句與多個異常
也可以使用相同的 except 語句來處理多個異常,如下所示:
try: Do you operations here; ...................... except(Exception1[, Exception2[,...ExceptionN]]]): If there is any exception from the given exception list, then execute this block. ...................... else: If there is no exception then execute this block.
標準異常
這是在Python提供一個標準異常的列表: 標準異常
try-finally 子句
可以使用try:塊連同try:塊一起。finally塊是一個地方放置代碼必須執行,無論在try塊是否引發異常代碼都會執行。try-finally語句的語法是這樣的:
try: Do you operations here; ...................... Due to any exception, this may be skipped. finally: This would always be executed. ......................
發生異常的參數
一個異常可以有一個參數,它是一個值,該值給出了有關問題的其他信息。 異常參數的內容各不相同。可以通過不同的子句中提供的變量,捕獲異常的參數如下所示:
try: Do you operations here; ...................... except ExceptionType, Argument: You can print value of Argument here...
引發一個異常
可以通過使用 raise 語句的幾種方式引發異常。一般 raise 語句的語法。
語法
raise [Exception [, args [, traceback]]]
用戶定義的異常
Python中,還可以通過內置的異常標準的派生類來創建自己的異常類。
這裡是一個例子有關 RuntimeError. 這裡說的是從 RuntimeError 類創建一個子類。當需要顯示更具體的信息時,一個異常被捕獲,這非常有用。
在try塊,用戶定義的異常引發,陷入在 except 塊中。變量e被用來創建 Networkerror 類的一個實例。
class Networkerror(RuntimeError): def __init__(self, arg): self.args = arg
所以一旦上麵的類定義後,可以按如下引發的異常:
try: raise Networkerror("Bad hostname") except Networkerror,e: print e.args
創建類
class語句創建一個新的類定義。 類的名稱緊跟在關鍵字class後,接著又跟一個冒號,如下所示:
class ClassName: 'Optional class documentation string' class_suite
-
這個類可以通過 ClassName.__doc__ 訪問一個文檔字符串
-
class_suite包括所有組件語句,定義類成員,數據屬性和函數。
創建實例對象:
要創建一個類的實例,調用類使用類名和傳遞參數給__init__方法接收。
"This would create first object of Employee class" emp1 = Employee("Zara", 2000) "This would create second object of Employee class" emp2 = Employee("Manni", 5000)
訪問屬性
可以訪問使用點(.)對象的運算符來訪問對象的屬性。類變量會使用類名來訪問,如下所示:
emp1.displayEmployee() emp2.displayEmployee() print "Total Employee %d" % Employee.empCount
內置類的屬性
每個Python類保存有下列內置屬性,它們可以使用點運算符像任何其他屬性來訪問:
-
__dict__ : 字典包含類的命名空間。
-
__doc__ : 類文檔字符串,或者如果是None那麼表示未定義。
-
__name__: 類名
-
__module__: 其中類定義的模塊名稱。此屬性在交互模式為“__main__”。
-
__bases__ : 一個可能為空的元組包含基類,其基類列表為出現的順序。
銷毀對象(垃圾回收)
Python刪除不需要的對象(內置類型或類實例)會自動釋放內存空間。由Python周期性回收的內存塊,不再是在使用過程中回收被稱為垃圾收集。
Python的垃圾收集程序執行過程中運行,當一個對象的引用計數為零時被觸發。一個對象的引用計數變化為彆名的數量指向它改變:
當它分配一個新的名稱或放置在容器(列表,元組,或字典)的對象的引用計數增加。當它使用 del 刪除對象減少引用計數 ,它引用被重新分配,或者其參考超出作用域。當一個對象的引用計數為零,Python會自動收集它。
類繼承
相反,從頭開始,可以通過在新類名稱後列表括號中的父類,從預先存在的類派生它來創建一個類:
子類繼承父類的屬性,可以使用這些屬性,就好像是在子類中定義一樣。從父類,子類還可以重寫數據成員和方法。
語法
派生類的聲明很像它們的父類;然而,從類名之後給出繼承的基類的列表:
class SubClassName (ParentClass1[, ParentClass2, ...]): 'Optional class documentation string' class_suite
重載方法
隨時可以覆蓋父類的方法。其中一個覆蓋父類方法的原因,是因為可能想在在子類中特殊或實現不同的功能。
class Parent: # define parent class def myMethod(self): print 'Calling parent method' class Child(Parent): # define child class def myMethod(self): print 'Calling child method' c = Child() # instance of child c.myMethod() # child calls overridden method
重載方法的基礎
下表列出了一些通用的功能,可以在自己的類中覆蓋:
| SN | 方法,說明與示例調用 |
|---|---|
| 1 |
__init__ ( self [,args...] ) 構造函數(任何可選參數) 調用示例 : obj = className(args) |
| 2 |
__del__( self ) 析構函數,刪除對象 調用示例 : dell obj |
| 3 |
__repr__( self ) 求值的字符串表示 調用示例 : repr(obj) |
| 4 |
__str__( self ) 可打印字符串表示 調用示例 : str(obj) |
| 5 |
__cmp__ ( self, x ) 對象比較 調用示例 : cmp(obj, x) |
運算符重載
假設我們已經創建了一個Vector類來表示二維向量。 當使用加運算符來添加它們,會發生什麼?最有可能Python會責罵我們。
但是可以定義 __add__ 方法類進行向量加法,然後相加運算符的行為也會按預期:
#!/usr/bin/python class Vector: def __init__(self, a, b): self.a = a self.b = b def __str__(self): return 'Vector (%d, %d)' % (self.a, self.b) def __add__(self,other): return Vector(self.a + other.a, self.b + other.b) v1 = Vector(2,10) v2 = Vector(5,-2) print v1 + v2
數據隱藏
一個對象的屬性可以或不可以在類定義外部可見。對於這些情況,可以命名以雙下劃線前綴屬性,這些屬性將不會直接外部可見:
#!/usr/bin/python class JustCounter: __secretCount = 0 def count(self): self.__secretCount += 1 print self.__secretCount counter = JustCounter() counter.count() counter.count() print counter.__secretCount
正則表達式是字符的特殊序列,可幫助匹配或查找其他字符串或設置字符串, 使用模式在特殊的語法。正則表達式被廣泛應用於UNIX的世界中。
Python中的模塊re提供了Perl般的正則表達式的全麵支持。 如果在編譯或使用正則表達式時發生錯誤,re模塊引發異常re.error。
我們將包括在其中將用於處理的正則表達式的兩個重要功能。但是,首先:當它們在正則表達式中使用這此字符將有特殊的含義。 為了避免任何混亂當使用正則表達式處理時,我們會用原始字符串為 r'expression'.
match 函數
此函數嘗試重新模式匹配字符串並可選標誌(flags)。
下麵是此函數的語法:
re.match(pattern, string, flags=0)
這裡是參數的說明:
| 參數 | 描述 |
|---|---|
| pattern | 這是正則表達式將要匹配。 |
| string | 這是一個將要搜索匹配的模式的字符串 |
| flags | 可以以互斥指定不同的標誌 OR (|). 這些是列於下表中的修辭符。 |
re.match 函數成功返回匹配對象,失敗返回 None。我們可以使用 group(num) 或 groups() 匹配對象的函數來獲取匹配的表達式。
| 匹配對象的方法 | 描述 |
|---|---|
| group(num=0) | 這個方法返回整個匹配(或指定分組num) |
| groups() | 方法返回所有匹配的子組中的一個元組(空,如果冇有發現任何) |
search 函數
此函數查找字符串內使用可選的標誌第一次出現的RE模式。
下麵是此函數語法的:
re.string(pattern, string, flags=0)
這裡是參數的說明:
| 參數 | 描述 |
|---|---|
| pattern | 這是正則表達式匹配。 |
| string | 這是一個將要搜索匹配的模式的字符串 |
| flags | 可以以互斥指定不同的標誌(flag) OR (|). 這些修辭符列於下表中。 |
re.search函數返回成功則匹配的對象,失敗則返回None。我們將使用 group(num) 或 groups() 匹配對象的函數來得到匹配的表達式。
| 匹配對象的方法 | 描述 |
|---|---|
| group(num=0) | 這個方法返回整個匹配(或指定分組num) |
| groups() | 該方法返回所有匹配的子組中的一個元組(空,如果冇有找到) |
匹配VS搜索
Python的提供兩種不同的原語操作基於正則表達式:match匹配檢查匹配僅在字符串的開頭,當搜索檢查匹配字符串中的任何地方(這是Perl並默認的情況)。
搜索和替換
一些最重要re方法使用正則表達式為sub。
語法
sub(pattern, repl, string, max=0)
這種方法用repl替換所有在字符串的RE模式,全部替換,除非出現最大提供。方法將返回修改後的字符串。
正則表達式修飾符 - 選項標誌
正則表達式文字可能包括一個可選的修飾符來控製匹配的各個方麵。修飾符指定為可選標誌。可以提供多個以互斥 OR (|) 修改, 如前所示,並且可以由其中一個來表示:
| 修辭符 | 描述 |
|---|---|
| re.I | 執行不區分大小寫匹配。 |
| re.L | 根據當前的語言環境來解釋詞語。這種解釋影響按字母順序小組(\w 和 \W), 以及單詞邊界行為 (\b 和 \B) |
| re.M | 使得$匹配未端的一行(字符串不僅僅是末端),使^匹配任何行(不隻是字符串的開始)的開始。 |
| re.S | 使一個句點匹配任何字符,包括換行。 |
| re.U | 根據Unicode字符集解釋字母。這個標誌影響 \w, \W, \b, \B 的行為 |
| re.X | 許可 “cuter”正則表達式語法。 它忽略空格(除組[]內,或當一個反斜杠轉義),對待轉義#作為注釋標記。 |
正則表達式模式
除了控製字符, (+ ? . * ^ $ ( ) [ ] { } | \), 所有字符匹配匹配自己。可以通過使用一個反斜杠在控製字符之前進行轉義。
下表列出了正則表達式語法可在Python中使用。
| 模式 | 描述 |
|---|---|
| ^ | 匹配一行的開始 |
| $ | 匹配一行的結尾 |
| . | 匹配除了換行符的任何單個字符。使用-m選項也可允許它匹配換行符 |
| [...] | 匹配括號內任何單個字符 |
| [^...] | 匹配任何不在括號內的單個字符 |
| re* | 匹配0個或多個出現在前麵表達式 |
| re+ | 匹配0或1出現在前麵表達式 |
| re{ n} | 精確匹配n個前麵表達式的數目 |
| re{ n,} | 匹配n次或多次出現前麵表達式 |
| re{ n, m} | 匹配至少n和最多m個在前麵表達式 |
| a| b | 匹配 a 或 b |
| (re) | 組正則表達式和匹配記住文本 |
| (?imx) | 臨時切換上i, m, 或 x 在一個正則表達式的選項。如果在括號,隻有該區域會受到影響 |
| (?-imx) | 臨時切換上i, m, 或 x 在一個正則表達式的選項。 隻有該區域會受到影響 |
| (?: re) | 組正則表達式無需記住匹配的文本 |
| (?imx: re) | 臨時切換上i, m, 或 x 在括號中的選項 |
| (?-imx: re) | 臨時關閉切換i, m, 或 x 在括號中的選項 |
| (?#...) | 注釋 |
| (?= re) | 指定位置使用模式。不必在一個範圍內 |
| (?! re) | 指定使用模式取相反位置,而不必一個範圍 |
| (?> re) | 匹配獨立模式而不回溯 |
| \w | 匹配單詞字符 |
| \W | 匹配非單詞字符 |
| \s | 匹配的空白符,相當於 [\t\n\r\f] |
| \S | 匹配非空白符 |
| \d | 匹配數字。相當於 [0-9] |
| \D | 匹配非數字 |
| \A | 匹配字符串的開始/開頭部分 |
| \Z | 匹配字符串的結尾。如果一個換行符存在,它隻匹配換行之前部分 |
| \z | 匹配字符串的結尾 |
| \G | 匹配一點,最後一次匹配結束 |
| \b | 匹配單詞邊界在括號之外。當匹配退格在(0×08)括號內 |
| \B | 匹配非單詞邊界 |
| \n, \t, etc. | 匹配換行符,回車,製表符等 |
| \1...\9 | 匹配第n個分組的子表達式 |
| \10 | 匹配n次分組的子表達式,如果它已經匹配。否則指的是字符碼的八進製表示。 |
正則表達式的例子
文字字符
| 示例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符類彆
| 示例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配任何一個小寫 元音 |
| [0-9] | 匹配任何數字; 如同 [0123456789] |
| [a-z] | 匹配任何小寫ASCII字母 |
| [A-Z] | 匹配任意大寫ASCII字母 |
| [a-zA-Z0-9] | 匹配任何上述的 |
| [^aeiou] | 匹配任何不是小寫元音 |
| [^0-9] | 匹配以外的任何其他數字 |
特殊字符類
| 示例 | 描述 |
|---|---|
| . | 匹配除換行符任何字符 |
| \d | 匹配一個數字: [0-9] |
| \D | 匹配一個非數字: [^0-9] |
| \s | 匹配一個空白字符: [ \t\r\n\f] |
| \S | 匹配非空白: [^ \t\r\n\f] |
| \w | 一個單詞字符: [A-Za-z0-9_] |
| \W | 匹配一個非單詞字符: [^A-Za-z0-9_] |
重複案例
| 示例 | 描述 |
|---|---|
| ruby? | 匹配 "rub" 或 "ruby": y 是可選的 |
| ruby* | 匹配"rub" 加上 0 或多個 ys |
| ruby+ | 匹配 "rub" 加上 1 或多個 ys |
| \d{3} | 精確匹配3位 |
| \d{3,} | 匹配3個或更多個數字 |
| \d{3,5} | 匹配3,4 或 5 位 |
非貪婪的重複
這符合最小的重複次數:
| 示例 | 描述 |
|---|---|
| <.*> | 貪婪的重複:匹配 "<python>perl>" |
| <.*?> | 非貪婪:匹配 "<python>" 在 "<python>perl>" |
用括號分組
| 示例 | 描述 |
|---|---|
| \D\d+ | 不分組: + 重複 \d |
| (\D\d)+ | 分組: + 重複\D\d 對 |
| ([Pp]ython(, )?)+ | 匹配 "Python", "Python, python, python" 等等 |
反向引用
這再次匹配先前匹配的分組
| 示例 | 描述 |
|---|---|
| ([Pp])ython&\1ails | 匹配 python&pails or Python&Pails |
| (['"])[^\1]*\1 | 單引號或雙引號字符串. \1 匹配不管第一組匹配。 \2 匹配不管第二組匹配等等。 |
備選方案
| 示例 | 描述 |
|---|---|
| python|perl | 匹配"python" 或 "perl" |
| rub(y|le)) | 匹配 "ruby" 或 "ruble" |
| Python(!+|\?) | "Python" 後麵跟著一個或更多 ! 或者一個 ? |
錨點
需要指定匹配位置
| 示例 | 描述 |
|---|---|
| ^Python | 匹配“Python”在一個字符串或內部行的開始 |
| Python$ | 匹配“Python”在一個字符串末尾或行 |
| \APython | 匹配“Python”在字符串的開始 |
| Python\Z | 匹配“Python”在字符串的結尾 |
| \bPython\b | 匹配“Python”在單詞邊界 |
| \brub\B | \B 非單詞是邊界:匹配 "rub" 在 "rube" 以及 "ruby" |
| Python(?=!) | 匹配“Python”,如果後麵跟一個感歎號 |
| Python(?!!) | 匹配“Python”,如果後麵不是帶有感歎號 |
使用括號特殊的語法:
| 示例 | 描述 |
|---|---|
| R(?#comment) | 匹配“R”。其餘全是注釋 |
| R(?i)uby | 不區分大小寫的,同時匹配 "uby" |
| R(?i:uby) | 與上述相同 |
| rub(?:y|le)) | 隻有分組,而無需創建\1逆向引用 |

