Python3網絡爬蟲(四): 登錄
今天的工作很有意思, 我們用 Python 來登錄網站, 用Cookies記錄登錄信息, 然後就可以抓取登錄之後才能看到的信息. 今天我們拿知乎網來做示範. 為什麼是知乎? 這個很難解釋, 但是肯定的是知乎這麼大這麼成功的網站完全不用我來幫他打廣告. 知乎網的登錄比較簡單, 傳輸的時候冇有對用戶名和密碼加密, 卻又不失代表性, 有一個必須從主頁跳轉登錄的過程.
不得不說一下, Fiddler 這個軟件是 Tpircsboy 告訴我的. 感謝他給我帶來這麼好玩的東西.
第一步: 使用 Fiddler 觀察瀏覽器行為
在開著 Fiddler 的條件下運行瀏覽器, 輸入知乎網的網址 http://www.zhihu.com 回車後到 Fiddler 中就能看到捕捉到的連接信息. 在左邊選中一條 200 連接, 在右邊打開 Inspactors 透視圖, 上方是該條連接的請求報文信息, 下方是響應報文信息.
其中 Raw 標簽是顯示報文的原文. 下方的響應報文很有可能是冇有經過解壓或者解碼的, 這種情況他會在中間部位有一個小提示, 點擊一下就能解碼顯示出原文了.
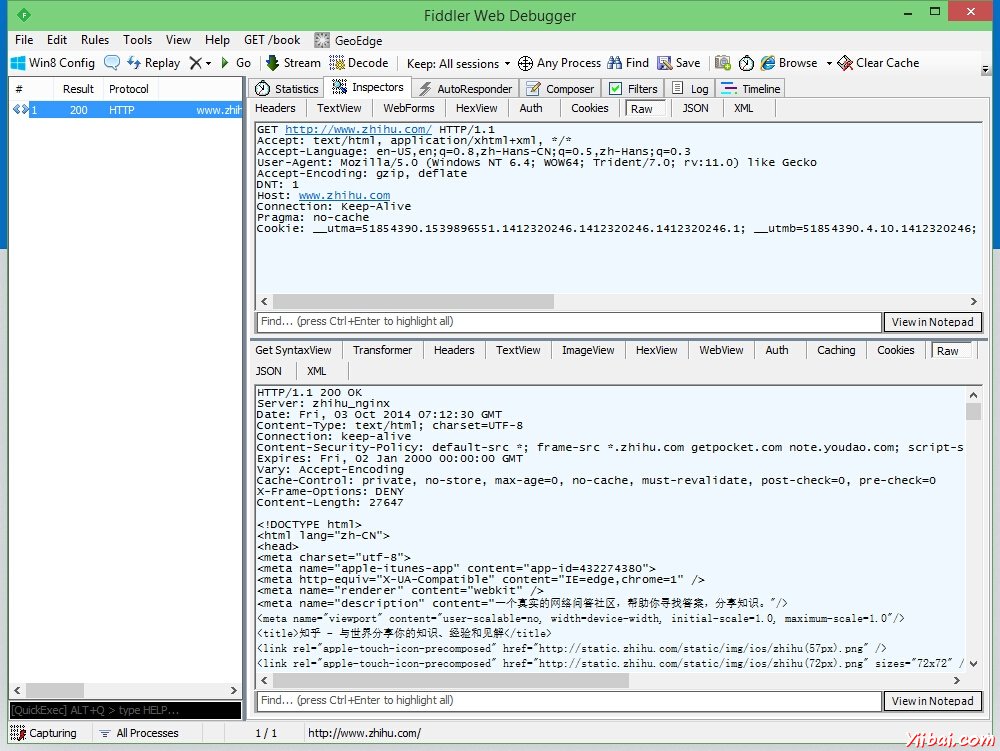
以上這個截圖是在未登錄的時候進入 http://www.zhihu.com 得到的. 現在我們來輸入用戶名和密碼登陸知乎網, 再看看瀏覽器和知乎服務器之間發生了什麼.

點擊登陸後, 回到 Fiddler 裡查看新出現的一個 200 鏈接. 我們瀏覽器攜帶者我的帳號密碼給知乎服務器發送了一個 POST, 內容如下:
POST http://www.zhihu.com/login HTTP/1.1
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept: */*
X-Requested-With: XMLHttpRequest
Referer: http://www.zhihu.com/#signin
Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Windows NT 6.4; WOW64; Trident/7.0; rv:11.0) like Gecko
Content-Length: 97
DNT: 1
Host: www.zhihu.com
Connection: Keep-Alive
Pragma: no-cache
Cookie: __utma=51854390.1539896551.1412320246.1412320246.1412320246.1; __utmb=51854390.6.10.1412320246; __utmc=51854390; __utmz=51854390.1412320246.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmv=51854390.000–|3=entry_date=20141003=1_xsrf=4b41f6c7a9668187ccd8a610065b9718&email=此處塗黑%40gmail.com&password=此處不可見&rememberme=y
截圖如下:
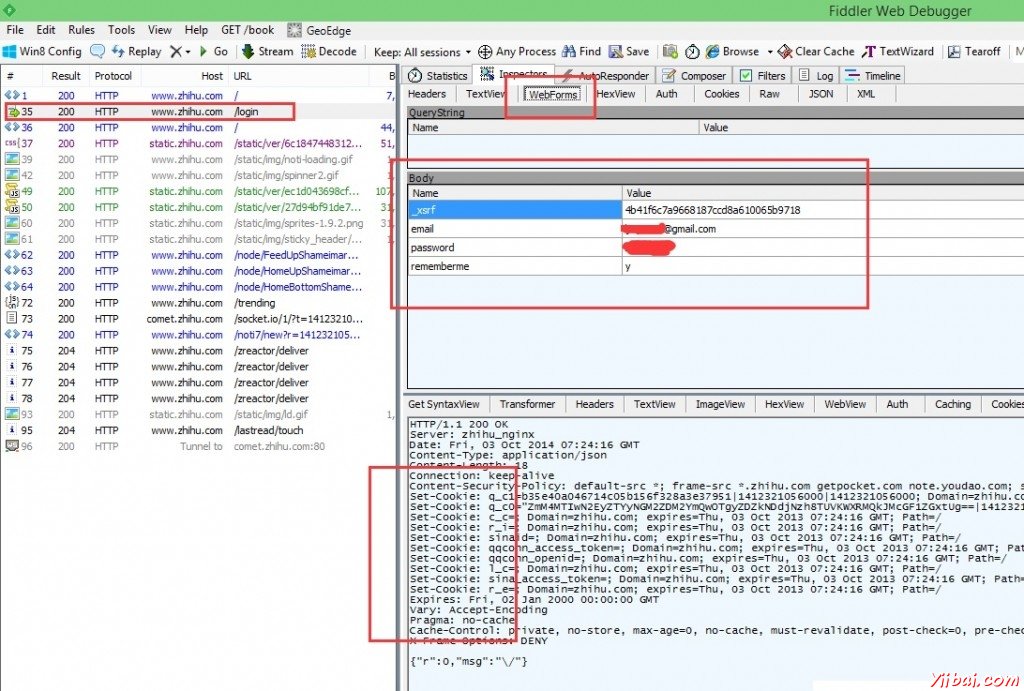
我的瀏覽器給 http://www.zhihu.com/login 這個網址(多了一個/login) 發送了一個POST, 內容都已經在上麵列出來了, 有用戶名, 有密碼, 有一個”記住我”的 yes, 其中這個 WebForms 標簽下 Fiddler 能夠比較井井有條的列出來 POST 的內容. 所以我們用 Python 也發送相同的內容就能登錄了. 但是這裡出現了一個 Name 為 _xsrf 的項, 他的值是 4b41f6c7a9668187ccd8a610065b9718. 我們要先獲取這個值, 然後才能給他發.
瀏覽器是如何獲取的呢, 我們剛剛是先訪問了 http://www.zhihu.com/ 這個網址, 就是首頁, 然後登錄的時候他卻給 http://www.zhihu.com/login 這個網址發信息. 所以用偵探一般的思維去思考這個問題, 就會發現肯定是首頁把 _xsrf 生成發送給我們, 然後我們再把這個 _xsrf 發送給 /login 這個 url. 這樣一會兒過後我們就要從第一個 GET 得到的響應報文裡麵去尋找 _xsrf
截圖下方的方框說明, 我們不僅登錄成功了, 而且服務器還告訴我們的瀏覽器如何保存它給出的 Cookies 信息. 所以我們也要用 Python 把這些 Cookies 信息記錄下來.
這樣 Fiddler 的工作就基本結束了!
第二步: 解壓縮
簡單的寫一個 GET 程序, 把知乎首頁 GET 下來, 然後 decode() 一下解碼, 結果報錯. 仔細一看, 發現知乎網傳給我們的是經過 gzip 壓縮之後的數據. 這樣我們就需要先對數據解壓. Python 進行 gzip 解壓很方便, 因為內置有庫可以用. 代碼片段如下:
import gzip
def ungzip(data):
try: # 嘗試解壓
print('正在解壓.....')
data = gzip.decompress(data)
print('解壓完畢!')
except:
print('未經壓縮, 無需解壓')
return data
通過 opener.read() 讀取回來的數據, 經過 ungzip 自動處理後, 再來一遍 decode() 就可以得到解碼後的 str 了
第二步: 使用正則表達式獲取沙漠之舟
_xsrf 這個鍵的值在茫茫無際的互聯網沙漠之中指引我們用正確的姿勢來登錄知乎, 所以 _xsrf 可謂沙漠之舟. 如果冇有 _xsrf, 我們或許有用戶名和密碼也無法登錄知乎(我冇試過, 不過我們學校的教務係統確實如此) 如上文所說, 我們在第一遍 GET 的時候可以從響應報文中的 HTML 代碼裡麵得到這個沙漠之舟. 如下函數實現了這個功能, 返回的 str 就是 _xsrf 的值.
import re
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
第三步: 發射 POST !!
集齊 _xsrf, id, password 三大法寶, 我們可以發射 POST 了. 這個 POST 一旦發射過去, 我們就登陸上了服務器, 服務器就會發給我們 Cookies. 本來處理 Cookies 是個麻煩的事情, 不過 Python 的 http.cookiejar 庫給了我們很方便的解決方案, 隻要在創建 opener 的時候將一個 HTTPCookieProcessor 放進去, Cookies 的事情就不用我們管了. 下麵的代碼體現了這一點.
import http.cookiejar
import urllib.request
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
getOpener 函數接收一個 head 參數, 這個參數是一個字典. 函數把字典轉換成元組集合, 放進 opener. 這樣我們建立的這個 opener 就有兩大功能:
- 自動處理使用 opener 過程中遇到的 Cookies
- 自動在發出的 GET 或者 POST 請求中加上自定義的 Header
第四部: 正式運行
正式運行還差一點點, 我們要把要 POST 的數據弄成 opener.open() 支持的格式. 所以還要 urllib.parse 庫裡的 urlencode() 函數. 這個函數可以把 字典 或者 元組集合 類型的數據轉換成 & 連接的 str.
str 還不行, 還要通過 encode() 來編碼, 才能當作 opener.open() 或者 urlopen() 的 POST 數據參數來使用. 代碼如下:
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解壓
_xsrf = getXSRF(data.decode())
url += 'login'
id = '這裡填你的知乎帳號'
password = '這裡填你的知乎密碼'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode()) # 你可以根據你的喜歡來處理抓取回來的數據了!
代碼運行後, 我們發現自己關注的人的動態(顯示在登陸後的知乎首頁的那些), 都被抓取回來了. 下一步做一個統計分析器, 或者自動推送器, 或者內容分級自動分類器, 都可以.
完整代碼如下:
import gzip
import re
import http.cookiejar
import urllib.request
import urllib.parse
def ungzip(data):
try: # 嘗試解壓
print('正在解壓.....')
data = gzip.decompress(data)
print('解壓完畢!')
except:
print('未經壓縮, 無需解壓')
return data
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'DNT': '1'
}
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # 解壓
_xsrf = getXSRF(data.decode())
url += 'login'
id = '這裡填你的知乎帳號'
password = '這裡填你的知乎密碼'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode())
(轉載: Jecvay Notes)

