Python 3開發網絡爬蟲(二)
上一回, 我學會了
- 用偽代碼寫出爬蟲的主要框架;
- 用Python的urllib.request庫抓取指定url的頁麵;
- 用Python的urllib.parse庫對普通字符串轉符合url的字符串.
這一回, 開始用Python將偽代碼中的所有部分實現. 由於文章的標題就是”零基礎”, 因此會先把用到的兩種數據結構隊列和集合介紹一下. 而對於”正則表達式“部分, 限於篇幅不能介紹, 但給出我比較喜歡的幾個參考資料.
Python的隊列
在爬蟲程序中, 用到了廣度優先搜索(BFS)算法. 這個算法用到的數據結構就是隊列.
Python的List功能已經足夠完成隊列的功能, 可以用 append() 來向隊尾添加元素, 可以用類似數組的方式來獲取隊首元素, 可以用 pop(0) 來彈出隊首元素. 但是List用來完成隊列功能其實是低效率的, 因為List在隊首使用 pop(0) 和 insert() 都是效率比較低的, Python官方建議使用collection.deque來高效的完成隊列任務.
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry") # Terry 入隊
queue.append("Graham") # Graham 入隊
queue.popleft() # 隊首元素出隊
#輸出: 'Eric'
queue.popleft() # 隊首元素出隊
#輸出: 'John'
queue # 隊列中剩下的元素
#輸出: deque(['Michael', 'Terry', 'Graham'])
(以上例子引用自官方文檔)
Python的集合
在爬蟲程序中, 為了不重複爬那些已經爬過的網站, 我們需要把爬過的頁麵的url放進集合中, 在每一次要爬某一個url之前, 先看看集合裡麵是否已經存在. 如果已經存在, 我們就跳過這個url; 如果不存在, 我們先把url放入集合中, 然後再去爬這個頁麵.
Python提供了set這種數據結構. set是一種無序的, 不包含重複元素的結構. 一般用來測試是否已經包含了某元素, 或者用來對眾多元素們去重. 與數學中的集合論同樣, 他支持的運算有交, 並, 差, 對稱差.
創建一個set可以用 set() 函數或者花括號 {} . 但是創建一個空集是不能使用一個花括號的, 隻能用 set() 函數. 因為一個空的花括號創建的是一個字典數據結構. 以下同樣是Python官網提供的示例.
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 這裡演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判斷元素是否在集合內
True
>>> 'crabgrass' in basket
False
>>> # 下麵展示兩個集合間的運算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同時包含於a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'
其實我們隻是用到其中的快速判斷元素是否在集合內的功能, 以及集合的並運算.
Python的正則表達式
在爬蟲程序中, 爬回來的數據是一個字符串, 字符串的內容是頁麵的html代碼. 我們要從字符串中, 提取出頁麵提到過的所有url. 這就要求爬蟲程序要有簡單的字符串處理能力, 而正則表達式可以很輕鬆的完成這一任務.
參考資料
雖然正則表達式功能異常強大, 很多實際上用的規則也非常巧妙, 真正熟練正則表達式需要比較長的實踐鍛煉. 不過我們隻需要掌握如何使用正則表達式在一個字符串中, 把所有的url都找出來, 就可以了. 如果實在想要跳過這一部分, 可以在網上找到很多現成的匹配url的表達式, 拿來用即可.
Python網絡爬蟲Ver 1.0 alpha
有了以上鋪墊, 終於可以開始寫真正的爬蟲了. 我選擇的入口地址是Fenng叔的Startup News, 我想Fenng叔剛剛拿到7000萬美金融資, 不會介意大家的爬蟲去光臨他家的小站吧. 這個爬蟲雖然可以勉強運行起來, 但是由於缺乏異常處理, 隻能爬些靜態頁麵, 也不會分辨什麼是靜態什麼是動態, 碰到什麼情況應該跳過, 所以工作一會兒就要敗下陣來.
import re
import urllib.request
import urllib
from collections import deque
queue = deque()
visited = set()
url = 'http://news.dbanotes.net' # 入口頁麵, 可以換成彆的
queue.append(url)
cnt = 0
while queue:
url = queue.popleft() # 隊首元素出隊
visited |= {url} # 標記為已訪問
print('已經抓取: ' + str(cnt) + ' 正在抓取 <--- ' + url)
cnt += 1
urlop = urllib.request.urlopen(url)
if 'html' not in urlop.getheader('Content-Type'):
continue
# 避免程序異常中止, 用try..catch處理異常
try:
data = urlop.read().decode('utf-8')
except:
continue
# 正則表達式提取頁麵中所有隊列, 並判斷是否已經訪問過, 然後加入待爬隊列
linkre = re.compile('href=\"(.+?)\"')
for x in linkre.findall(data):
if 'http' in x and x not in visited:
queue.append(x)
print('加入隊列 ---> ' + x)
這個版本的爬蟲使用的正則表達式是
'href=\"(.+?)\"'
所以會把那些.ico或者.jpg的鏈接都爬下來. 這樣read()了之後碰上decode(‘utf-8′)就要拋出異常. 因此我們用getheader()函數來獲取抓取到的文件類型, 是html再繼續分析其中的鏈接.
if 'html' not in urlop.getheader('Content-Type'):
continue
但是即使是這樣, 依然有些網站運行decode()會異常. 因此我們把decode()函數用try..catch語句包圍住, 這樣他就不會導致程序中止. 程序運行效果圖如下:
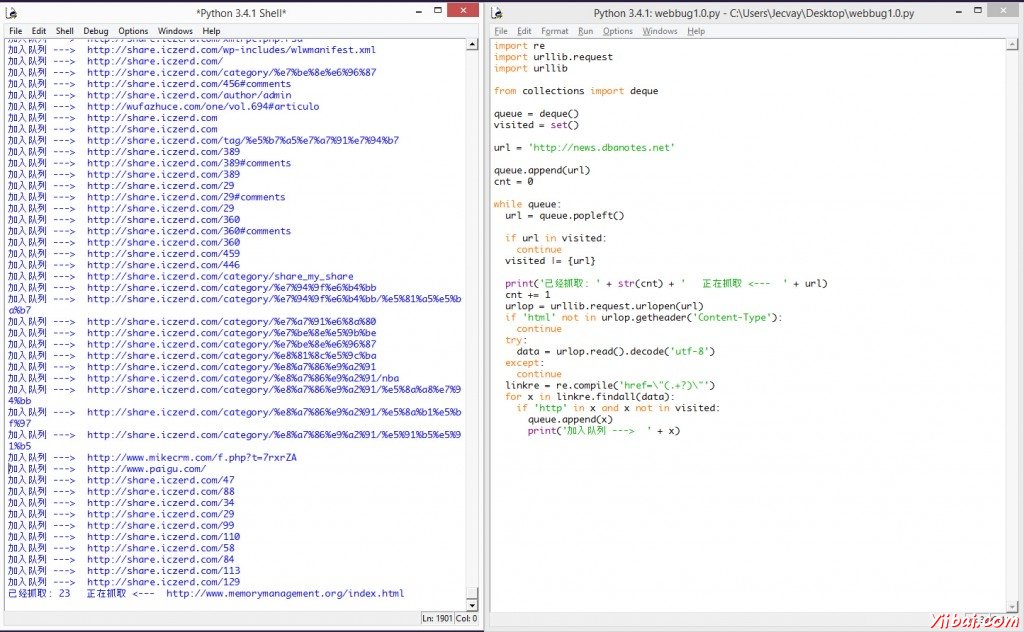
爬蟲是可以工作了, 但是在碰到連不上的鏈接的時候, 它並不會超時跳過. 而且爬到的內容並冇有進行處理, 冇有獲取對我們有價值的信息, 也冇有保存到本地. 下次我們可以完善這個alpha版本.

