TIKA內容提取
Tika使用不同的解析器庫來提取給解析器的內容。它選擇了正確的語法分析器提取給定的文檔類型。
解析文件,一般用於Tika外觀facade類的parseToString()方法。下麵顯示的是所涉及分析過程的步驟和這些由Tika的ParsertoString()方法提取。
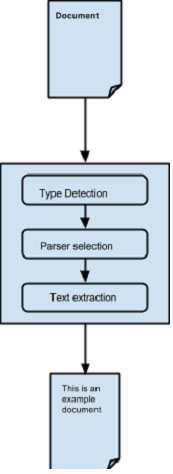
抽象的分析過程:
-
最初,當我們傳一個文件到Tika,它使用與之適合的類型檢測機製和檢測文件類型。
-
一旦文檔類型是已知的,它選擇從解析器庫中合適的解析器。解析器庫中包含的類使用外部庫。
-
然後將文檔傳送到選擇將解析的內容,提取文本,並且還拋出了不可讀格式異常解析器。
使用Tika內容提取
下麵給出的是程序使用Tika facade 類從文件中提取文本:
import java.io.File; import java.io.IOException; import org.apache.tika.Tika; import org.apache.tika.exception.TikaException; import org.xml.sax.SAXException; public class TikaExtraction { public static void main(final String[] args) throws IOException, TikaException { //Assume sample.txt is in your current directory File file = new File("sample.txt"); //Instantiating Tika facade class Tika tika = new Tika(); String filecontent = tika.parseToString(file); System.out.println("Extracted Content: " + filecontent); } }
將以上代碼保存為TikaExtraction.java並在命令提示符下運行:
javac TikaExtraction.java java TikaExtraction
注意:假設 sample.txt 是具有下列內容。
Hi students welcome to yiibai
它提供了以下的輸出:
Extracted Content: Hi students welcome to yiibai
使用Parser接口內容提取
Tika 解析器包提供了使用它可以分析一個文本文檔的幾個接口和類。下麵給出的是org.apache.tika.parser包的框架圖。
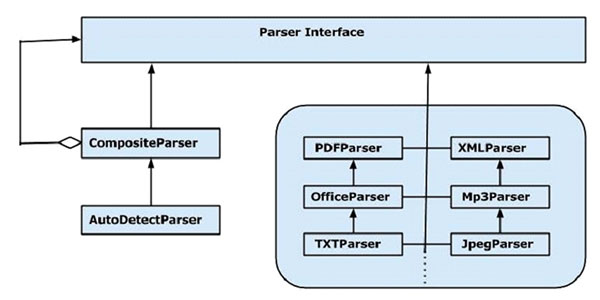
有幾個可用的解析器類,如PDF格式分析器,Mp3Passer,OfficeParser等,逐一分析各自的文件。所有這些類都實現了解析器接口。
CompositeParser
給出的圖表顯示Tika通用解析器類CompositeParser 主AutoDetectParser。由於CompositeParser類遵循複合設計模式,可以用一組解析器實例作為一個單獨的解析器。CompositeParser類也可以訪問所有實現解析器接口的類。
AutoDetectParser
這是CompositeParser的子類,它提供了自動類型檢測。使用此功能,AutoDetectParser自動發送收到的文件到使用該複合方法適當分析器類。
parse()方法
除了parseToString(),還可以使用分析器接口的parse()方法。該方法的原型如下所示。
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)
下表列出了它接受作為參數的四個對象。
| S.No. | 對象及描述 |
|---|---|
| 1 |
InputStream stream 包含任何文件的InputStream對象的內容 |
| 2 |
ContentHandler handler Tika通過文檔作為XHTML內容到此處理,此後該文件正在使用SAX API處理。它提供了在一個文件有效的後處理的內容。 |
| 3 |
Metadata metadata 元數據對象是用來既作為源和文件的元數據的目標。 |
| 4 |
ParseContext context 此對象使用在如遇有客戶端應用程序想要定製解析過程。 |
例如:
下麵給出一個例子,說明如何使用 parse()方法。
步驟 1:
要使用解析器接口的parse()方法,實例化任何為其提供實現這個接口的類。
也有個彆解析器類,如PDFParser,OfficeParser,XMLParser等等。可以使用這些個人文件解析器。或者也可以使用CompositeParser或AutoDetectParser在內部使用的所有解析器類,並提取使用合適的解析器文檔的內容。
Parser parser = new AutoDetectParser(); (or) Parser parser = new CompositeParser(); (or) object of any individual parsers given in Tika Library
步驟 2:
創建一個處理類的對象。下麵給出的是三個內容處理程序:
| S.No. | 類及描述 |
|---|---|
| 1 |
BodyContentHandler 這個類采用XHTML輸出的主體部分,並寫入該內容到輸出寫入或輸出流。然後重定向XHTML內容到另一個內容處理程序實例。 |
| 2 |
LinkContentHandler 這個類檢測,並挑選XHTML文檔的所有H-參考標簽和轉發那些使用類似網絡爬蟲工具。 |
| 3 |
TeeContentHandler 這個類可以幫助在同時使用多個工具。 |
由於我們的目標是要提取的文件的文本內容,實例化BodyContentHandler如下圖所示:
BodyContentHandler handler = new BodyContentHandler( );
步驟 3:
創建的元數據對象,如下所示:
Metadata metadata = new Metadata();
步驟 4:
創建任何輸入流對象,並通過您的文件應該被提取到它。
FileInputstream
通過將文件路徑作為參數實例化一個文件對象,這個對象傳遞給的FileInputStream類的構造函數。
注意:傳遞給文件對象的路徑不應包含空格。
使用這些輸入流類的問題是,它們不支持隨機訪問讀取,來高效地處理某些文件格式是必需。要解決此問題,Tika提供TikaInputStream。
File file=new File(filepath) FileInputStream inputstream=new FileInputStream(file); (or) InputStream stream = TikaInputStream.get(new File(filename));
步驟 5:
創建一個解析的上下文對象,如下所示:
ParseContext context =new ParseContext();
步驟 6:
實例化解析器對象,調用parse方法,並通過所有需要的對象,如下麵的原型:
parser.parse(inputstream, handler, metadata, context);
下麵給出的是程序使用的解析器接口內容提取:
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.AutoDetectParser; import org.apache.tika.parser.ParseContext; import org.apache.tika.parser.Parser; import org.apache.tika.sax.BodyContentHandler; import org.xml.sax.SAXException; public class ParserExtraction { public static void main(final String[] args) throws IOException,SAXException, TikaException { //Assume sample.txt is in your current directory File file = new File("sample.txt"); //parse method parameters Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); //parsing the file parser.parse(inputstream, handler, metadata, context); System.out.println("File content : " + Handler.toString()); } }
將以上代碼保存為 ParserExtraction.java 並在命令提示符下運行:
javac ParserExtraction.java java ParserExtraction
假設 sample.txt 包含以下內容。
Hi students welcome to yiibai
它提供了以下的輸出:
File content : Hi students welcome to yiibai

