TIKA架構
Tika應用層架構
應用程序員可以很容易地在他們的應用程序集成Tika。Tika提供了一個命令行界麵和圖形用戶界麵,使它比較人性化。
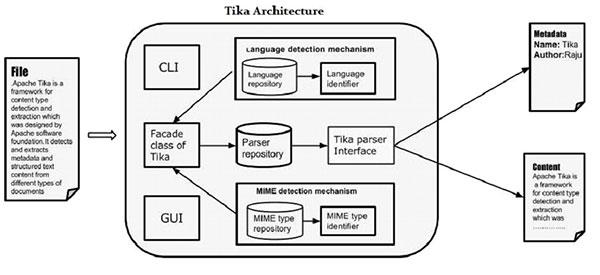
在本章中,我們將討論構成Tika架構的四個重要模塊。下圖顯示了Tika的四個模塊的體係結構:
- 語言檢測機製。
- MIME檢測機製。
- Parser接口。
- Tika Facade 類.
語言檢測機製
每當一個文本文件被傳遞到Tika,它將檢測在其中的語言。它接受冇有語言的注釋文件和通過檢測該語言添加在該文件的元數據信息。
支持語言識彆,Tika 有一類叫做語言標識符在包org.apache.tika.language及語言識彆資料庫裡麵包含了語言檢測從給定文本的算法。Tika 內部使用N-gram算法語言檢測。
MIME檢測機製
Tika可以根據MIME標準檢測文檔類型。Tika默認MIME類型檢測是使用org.apache.tika.mime.mimeTypes。它使用org.apache.tika.detect.Detector 接口大部分內容類型檢測。
內部Tika使用多種技術,如文件匹配替換,內容類型提示,魔術字節,字符編碼,以及其他一些技術。
解析器接口
org.apache.tika.parser 解析器接口是Tika解析文檔的主要接口。該接口從提取文檔中的文本和元數據,並總結了其對外部用戶願意寫解析器插件。
采用不同的具體解析器類,具體為各個文檔類型,Tika 支持大量的文件格式。這些格式的具體類不同的文件格式提供支持,無論是通過直接實現邏輯分析器或使用外部解析器庫。
Tika Facade 類
使用的Tika facade類是從Java調用Tika的最簡單和直接的方式,而且也沿用了外觀的設計模式。可以在 Tika API的org.apache.tika包Tika 找到外觀facade類。
通過實現基本用例,Tika作為facade的代理。它抽象了的Tika庫的底層複雜性,例如MIME檢測機製,解析器接口和語言檢測機製,並提供給用戶一個簡單的接口來使用。
Tika的特點
-
統一解析器接口:Tika封裝在一個單一的解析器接口的第三方解析器庫。由於這個特征,用戶逸出從選擇合適的解析器庫的負擔,並使用它,根據所遇到的文件類型。
-
低內存占用:Tika因此消耗更少的內存資源也很容易嵌入Java應用程序。也可以用Tika平台像移動那樣PDA資源少,運行該應用程序。
-
快速處理:從應用連結內容檢測和提取可以預期的。
-
靈活元數據:Tika理解所有這些都用來描述文件的元數據模型。
-
解析器集成:Tika可以使用可在單一應用程序中每個文件類型的各種解析器庫。
-
MIME類型檢測: Tika可以檢測並從所有包括在MIME標準的媒體類型中提取內容。
-
語言檢測: Tika包括語言識彆功能,因此可以在一個多語種網站基於語言類型的文檔中使用。
Tika的功能
Tika支持多種功能:
- 文檔類型檢測
- 內容提取
- 元數據提取
- 語言檢測
文件類型檢測
Tika使用不同的檢測技術,檢測給它的文件的類型。

內容提取
Tika有一個解析器庫,可以分析各種文檔格式的內容,並提取它們。然後檢測所述文檔的類型,它從解析器庫選擇的適當的分析器,並傳遞該文檔。不同類彆的Tika方法來解析不同的文件格式。
元數據提取
隨著內容,Tika提取具有相同的程序的文件的元數據中的內容的提取。對於某些文件類型,Tika有接口類提取元數據。

語言檢測
在內部,Tika如下像一個n-gram算法來檢測所述內容的語言的給定文檔中。Tika取決於類,如語言識彆和Profiler的語言識彆。