點擊樣本列表中的Airlines Delay Flow連結,如下圖所示;

確認後,將加載新筆記本。
Clearing All Outputs
在解釋筆記本中的代碼語句之前,讓我們先清除所有輸出,然後逐步運行筆記本。要清除所有輸出,請選擇以下菜單選項−
Flow / Clear All Cell Contents
下面的截圖顯示了這一點;

清除所有輸出後,我們將分別運行筆記本中的每個單元格並檢查其輸出。
Running the First Cell
單擊第一個單元格。左側將出現一個紅色標誌,指示單元格已選定。如下截圖所示;

這個單元格的內容只是用MarkDown(MD)語言編寫的程序注釋。內容描述了加載的應用程式的功能。要運行單元格,請單擊下面螢幕截圖中顯示的運行圖標−

由於當前單元格中沒有可執行代碼,因此在單元格下面看不到任何輸出。光標現在會自動移動到下一個準備執行的單元格。
Importing Data
下一個單元格包含以下Python語句−
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
語句將allyears2k.csv文件從Amazon AWS導入到系統中。運行單元格時,它將導入文件並提供以下輸出。

Setting Up Data Parser
現在,我們需要解析數據並使其適合我們的ML算法。這是使用以下命令完成的−
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]
執行上述語句後,將出現安裝配置對話框。該對話框允許您對文件進行多個分析設置。如下截圖所示;
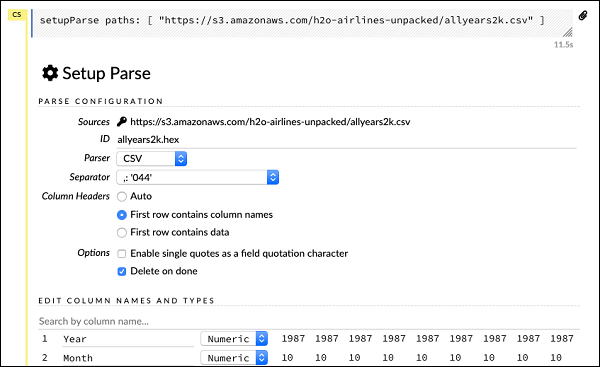
在此對話框中,您可以從給定的下拉列表中選擇所需的解析器,並設置其他參數,如欄位分隔符等。
Parsing Data
下一個語句實際上使用上述配置解析數據文件,它是一個長語句,如下所示−
parseFiles paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"] destination_frame: "allyears2k.hex" parse_type: "CSV" separator: 44 number_columns: 31 single_quotes: false column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime", "ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum", "ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay", "Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode", "Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay", "LateAircraftDelay","IsArrDelayed","IsDepDelayed"] column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric" ,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric", "Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum", "Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"] delete_on_done: true check_header: 1 chunk_size: 4194304
請注意,您在配置框中設置的參數已在上述代碼中列出。現在,運行這個單元。一段時間後,解析完成,您將看到以下輸出−

Examining Dataframe
在處理之後,它生成一個數據幀,可以使用以下語句檢查它−
getFrameSummary "allyears2k.hex"
在執行上述語句時,您將看到以下輸出–-;

現在,您的數據可以輸入機器學習算法了。
下一個語句是一個程序注釋,說明我們將使用回歸模型,並指定預設的正則化和lambda值。
Building the Model
接下來是最重要的聲明,那就是構建模型本身。這在下面的語句中有詳細說明;
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}
我們使用廣義線性模型集glm,它是一個具有二項族類型集的廣義線性模型集。您可以在上面的語句中看到這些突出顯示。在我們的例子中,預期的輸出是二進位的,所以我們使用二項式類型。您可以自己檢查其他參數;例如,查看前面指定的alpha和lambda。有關所有參數的說明,請參閱GLM模型文檔。
現在,運行這個語句。在執行時,將生成以下輸出;
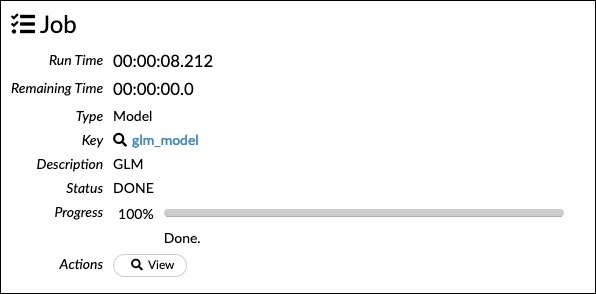
當然,在你的機器上執行的時間是不同的。下面是這個示例代碼中最有趣的部分。
Examining Output
我們只需使用以下語句輸出我們構建的模型−
getModel "glm_model"
注意glm_model是我們在前面的語句中構建模型時指定爲model_ID參數的模型ID。這給了我們一個巨大的輸出,詳細說明了幾個不同參數的結果。報告的部分輸出顯示在下面的螢幕截圖中;

正如您在輸出中看到的,它說這是在數據集上運行廣義線性建模算法的結果。
在記分歷史的上方,您可以看到模型參數標籤,展開它,您將看到構建模型時使用的所有參數的列表。如下截圖所示。

同樣,每個標記提供特定類型的詳細輸出。自己展開各種標籤來研究不同類型的輸出。
Building Another Model
接下來,我們將在我們的數據框架上構建一個深入學習模型。示例代碼中的下一個語句只是一個程序注釋。下面的語句實際上是一個建模命令。如圖所示;
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}
正如您在上面的代碼中看到的,我們指定deeplearning來構建模型,其中幾個參數設置爲deeplearning模型文檔中指定的適當值。當您運行此語句時,它將比GLM模型構建花費更長的時間。模型構建完成後,您將看到以下輸出,儘管計時不同。

Examining Deep Learning Model Output
這將生成輸出類型,可以像前面那樣使用以下語句檢查輸出。
getModel "deeplearning_model"
我們將考慮如下所示的ROC曲線輸出,以供快速參考。

與前面的例子一樣,展開各個選項卡並研究不同的輸出。
Saving the Model
在研究了不同模型的輸出之後,您決定在生產環境中使用其中一個模型。H20允許您將此模型保存爲POJO(普通的舊Java對象)。
在輸出中展開最後一個標記預覽POJO,您將看到用於微調模型的Java代碼。在生產環境中使用此選項。

接下來,我們將學習H2O的一個非常令人興奮的特性,我們將學習如何使用AutoML來測試各種算法,並根據它們的性能對它們進行排名。