你有沒有被要求在一個巨大的資料庫上開發一個機器學習模型?通常,客戶會向您提供資料庫,並要求您做出某些預測,例如誰將是潛在的買家;如果能夠及早發現欺詐案件等。要回答這些問題,您的任務是開發一種機器學習算法,爲客戶的查詢提供答案。從頭開始開發機器學習算法不是一件容易的事情,當市場上有幾個現成的機器學習庫時,爲什麼要這樣做呢。
現在,您更願意使用這些庫,應用這些庫中經過良好測試的算法,並查看其性能。如果性能不在可接受的範圍內,您可以嘗試微調當前算法或嘗試完全不同的算法。
同樣,您可以在同一個數據集上嘗試多個算法,然後選擇滿足客戶要求的最佳算法。這就是水來救你的地方。它是一個開源的機器學習框架,有幾個被廣泛接受的ML算法的完整測試實現。你只需要從它龐大的存儲庫中提取算法並將其應用到你的數據集。它包含了最廣泛使用的統計和ML算法。
這裡提到的一些包括梯度增強機(GBM)、廣義線性模型(GLM)、深度學習等。不僅如此,它還支持AutoML功能,該功能將對數據集上不同算法的性能進行排序,從而減少您尋找性能最佳模型的工作。全世界18000多個組織都在使用H2O,爲了便於開發,H2O與R和Python有很好的接口。它是一個內存平台,提供卓越的性能。
在本教程中,您將首先學習使用Python和R選項在機器上安裝H2O。我們將了解如何在命令行中使用它,以便您了解它的工作行。如果您是一個Python愛好者,您可以使用Jupyter或您選擇的任何其他IDE來開發H2O應用程式。如果您喜歡R,可以使用RStudio進行開發。
在本教程中,我們將考慮一個例子來了解如何使用H2O,我們還將學習如何更改程序代碼中的算法,並將其性能與前面的算法進行比較。H2O還提供了一個基於web的工具來測試數據集上的不同算法。這叫做流。
本教程將向您介紹流的使用。同時,我們將討論AutoML的使用,它將識別數據集上性能最佳的算法。你不想學水嗎?繼續讀下去!
H2O - Installation
水可以配置和使用五種不同的選項,如下所示;
在Python中安裝
安裝在R中
基於Web的流GUI
哈多普。
水蟒雲
在我們隨後的章節中,您將看到基於可用選項的H2O安裝說明。您可能會使用其中一個選項。
在Python中安裝
要使用Python運行H2O,安裝需要幾個依賴項。所以讓我們開始安裝運行H2O的最小依賴集。
Installing Dependencies
要安裝依賴項,請執行以下pip命令−
$ pip install requests
打開控制台窗口並鍵入以上命令以安裝請求包。下面的螢幕截圖顯示了上述命令在我們的Mac機器上的執行情況;

安裝完請求後,您需要再安裝三個包,如下所示;
$ pip install tabulate $ pip install "colorama >= 0.3.8" $ pip install future
最新的依賴項列表可以在H2OGithub頁面上找到。撰寫本文時,頁面上列出了以下依賴項。
python 2. H2O — Installation pip >= 9.0.1 setuptools colorama >= 0.3.7 future >= 0.15.2
Removing Older Versions
安裝上述依賴項後,需要刪除任何現有的H2O安裝。爲此,請運行以下命令−
$ pip uninstall h2o
Installing the Latest Version
現在,讓我們使用以下命令安裝最新版本的H2O−
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
成功安裝後,您將在螢幕上看到以下消息顯示−
Installing collected packages: h2o Successfully installed h2o-3.26.0.1
Testing the Installation
爲了測試安裝,我們將運行H2O安裝中提供的一個示例應用程式。首先輸入以下命令啓動Python提示符−
$ Python3
一旦Python解釋器啓動,在Python命令提示符下鍵入以下Python語句−
>>>import h2o
上面的命令在程序中導入H2O包。接下來,使用以下命令初始化水系統−
>>>h2o.init()
您的螢幕將顯示集羣信息,在這個階段您應該查看以下內容&負;

現在,您可以運行示例代碼了。在Python提示符下鍵入以下命令並執行它。
>>>h2o.demo("glm")
演示由一個Python筆記本和一系列命令組成。執行每個命令後,其輸出將立即顯示在螢幕上,並要求您按鍵以繼續下一步。執行筆記本中最後一條語句的部分螢幕截圖如下所示;

在這個階段,Python安裝已經完成,您已經準備好進行自己的實驗了。
安裝在R中
爲R開發安裝H2O與爲Python安裝它非常相似,只是您將使用R prompt進行安裝。
Starting R Console
單擊機器上的R應用程式圖標啓動R控制台。控制台螢幕如下圖所示;

您的水安裝將在上述R提示下完成。如果您喜歡使用RStudio,請在R console子窗口中鍵入命令。
Removing Older Versions
首先,在R提示符下使用以下命令刪除舊版本−
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
Downloading Dependencies
使用以下代碼下載H2O的依賴項−
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}
Installing H2O
在R提示符下鍵入以下命令安裝H2O−
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))
下面的螢幕截圖顯示了預期的輸出;

有另一種方法可以在R中安裝水。
安裝在R中 from CRAN
要從CRAN安裝R,請在R提示符下使用以下命令−
> install.packages("h2o")
您將被要求選擇鏡子−
--- Please select a CRAN mirror for use in this session ---

螢幕上將顯示一個顯示鏡像站點列表的對話框。選擇最近的位置或您選擇的鏡像。
Testing Installation
在R提示符下,鍵入並運行以下代碼−
> library(h2o) > localH2O = h2o.init() > demo(h2o.kmeans)
生成的輸出將如以下螢幕截圖所示;

你在R的水裝置現在已經完成了。
Installing Web GUI Flow
要安裝GUI流,請從H20站點下載安裝文件。將下載的文件解壓縮到首選文件夾中。注意安裝中是否存在h2o.jar文件。在命令窗口中使用以下命令運行此文件−
$ java -jar h2o.jar
一段時間後,控制台窗口中將顯示以下內容。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms 07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:
要啓動流,請在瀏覽器中打開給定的URLhttp://localhost:54321。將出現以下螢幕−

在此階段,流安裝已完成。
Install on 哈多普。 / 水蟒雲
Unless you are a seasoned developer, you would not think of using H2O on Big Data. It is sufficient to say here that H2O models run efficiently on huge databases of several terabytes. If your data is on your 哈多普。 installation or in the Cloud, follow the steps given on H2O site to install it for your respective database.
既然您已經成功地在您的機器上安裝並測試了H2O,您就可以進行真正的開發了。首先,我們將從命令提示符看到開發過程。在接下來的課程中,我們將學習如何在水流量下進行模型測試。
Developing in Command Prompt
現在,讓我們考慮使用H2O對知名iris數據集的植物進行分類,該數據集可免費用於開發機器學習應用程式。
在shell窗口中鍵入以下命令來啓動Python解釋器−
$ Python3
這將啓動Python解釋器。使用以下命令導入h2o平台−
>>> import h2o
我們將使用隨機森林算法進行分類。這在H2ORandomForestEstimator包中提供。我們使用如下的import語句導入這個包;
>>> from h2o.estimators import H2ORandomForestEstimator
我們通過調用其init方法來初始化H2o環境。
>>> h2o.init()
成功初始化後,您應該會在控制台上看到以下消息以及集羣信息。
Checking whether there is an H2O instance running at http://localhost:54321 . connected.
現在,我們將在H2O中使用import_file方法導入iris數據。
>>> data = h2o.import_file('iris.csv')
進度將顯示在下面的螢幕截圖中;

將文件加載到內存中後,可以通過顯示加載表的前10行來驗證這一點。您可以使用head方法來執行此操作;
>>> data.head()
您將看到以下表格格式的輸出。

該表還顯示列名。我們將使用前四列作爲ML算法的特性,使用最後一列類作爲預測輸出。我們在對ML算法的調用中通過首先創建以下兩個變量來指定這一點。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] >>> output = 'class'
接下來,我們通過調用split_frame方法將數據分爲訓練和測試。
>>> train, test = data.split_frame(ratios = [0.8])
數據按80:20的比例分割。我們使用80%的數據進行培訓,20%用於測試。
現在,我們將內置的隨機森林模型加載到系統中。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
在上面的調用中,我們將樹的數量設置爲50,樹的最大深度設置爲20,交叉驗證的摺疊次數設置爲10。我們現在需要訓練這個模型。我們通過調用如下的train方法來實現這一點;
>>> model.train(x = features, y = output, training_frame = train)
train方法接收我們前面創建的作爲前兩個參數的特性和輸出。訓練數據集被設置爲train,這是我們完整數據集的80%。在培訓期間,您將看到這裡顯示的進度;
現在,隨著模型構建過程的結束,是測試模型的時候了。我們通過對訓練的模型對象調用model_performance方法來實現這一點。
>>> performance = model.model_performance(test_data=test)
在上面的方法調用中,我們將測試數據作爲參數發送。
現在是時候看看輸出了,這是我們模型的性能。只需列印性能即可完成此操作。
>>> print (performance)
這將爲您提供以下輸出&負;

輸出顯示均方誤差(MSE)、均方根誤差(RMSE)、對數損失甚至混淆矩陣。
Running in Jupyter
我們已經看到了命令的執行過程,也理解了每一行代碼的用途。您可以在Jupyter環境中運行整個代碼,一次運行一行或整個程序。這裡給出了完整的列表;
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)
運行代碼並觀察輸出。現在您可以理解在數據集上應用和測試隨機林算法是多麼容易。H20的威力遠遠超過這個能力。如果您想在同一個數據集上嘗試另一個模型,看看是否可以獲得更好的性能,該怎麼辦。這將在後面的章節中解釋。
Applying a Different Algorithm
現在,我們將學習如何將梯度增強算法應用到早期的數據集中,以了解其性能。在上面的完整列表中,您只需要做兩個小的更改,如下代碼中突出顯示的−
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)
運行該代碼,您將得到以下輸出−

只需將結果(如MSE、RMSE、混淆矩陣等)與先前的輸出進行比較,並決定將哪個結果用於生產部署。事實上,你可以應用幾種不同的算法來決定最適合你的目標。
H2O - Flow
在上一課中,您學習了使用命令行界面創建基於H2O的ML模型。H2O流實現了相同的目的,但有一個基於web的界面。
在下面的課程中,我將向您展示如何啓動H2O流並運行示例應用程式。
Starting H2O Flow
您先前下載的H2O安裝包含H2O.jar文件。要啓動H2O流,首先在命令提示符下運行這個jar−
$ java -jar h2o.jar
當jar成功運行時,您將在控制台上收到以下消息−
Open H2O Flow in your web browser: http://192.168.1.10:54321
現在,打開您選擇的瀏覽器並鍵入上面的URL。您將看到基於H2O的桌面,如圖所示;

這基本上是一個類似於Colab或Jupyter的筆記本。我將向您展示如何在本筆記本中加載和運行示例應用程式,同時解釋流中的各種功能。單擊上面螢幕上的「查看示例流」連結以查看提供的示例列表。
我將從示例中描述航空公司的延遲流示例。
H2O - Running Sample Application
點擊樣本列表中的Airlines Delay Flow連結,如下圖所示;

確認後,將加載新筆記本。
Clearing All Outputs
在解釋筆記本中的代碼語句之前,讓我們先清除所有輸出,然後逐步運行筆記本。要清除所有輸出,請選擇以下菜單選項−
Flow / Clear All Cell Contents
下面的截圖顯示了這一點;

清除所有輸出後,我們將分別運行筆記本中的每個單元格並檢查其輸出。
Running the First Cell
單擊第一個單元格。左側將出現一個紅色標誌,指示單元格已選定。如下截圖所示;

這個單元格的內容只是用MarkDown(MD)語言編寫的程序注釋。內容描述了加載的應用程式的功能。要運行單元格,請單擊下面螢幕截圖中顯示的運行圖標−

由於當前單元格中沒有可執行代碼,因此在單元格下面看不到任何輸出。光標現在會自動移動到下一個準備執行的單元格。
Importing Data
下一個單元格包含以下Python語句−
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
語句將allyears2k.csv文件從Amazon AWS導入到系統中。運行單元格時,它將導入文件並提供以下輸出。

Setting Up Data Parser
現在,我們需要解析數據並使其適合我們的ML算法。這是使用以下命令完成的−
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]
執行上述語句後,將出現安裝配置對話框。該對話框允許您對文件進行多個分析設置。如下截圖所示;
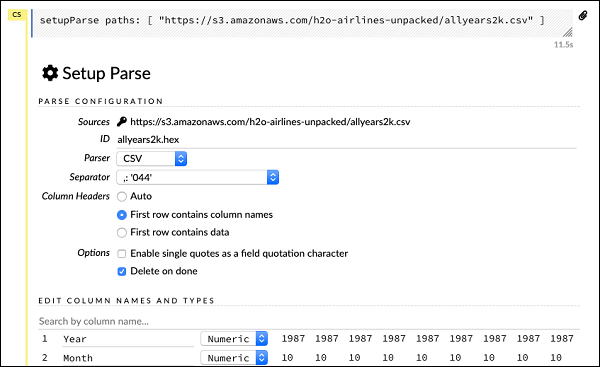
在此對話框中,您可以從給定的下拉列表中選擇所需的解析器,並設置其他參數,如欄位分隔符等。
Parsing Data
下一個語句實際上使用上述配置解析數據文件,它是一個長語句,如下所示−
parseFiles paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"] destination_frame: "allyears2k.hex" parse_type: "CSV" separator: 44 number_columns: 31 single_quotes: false column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime", "ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum", "ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay", "Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode", "Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay", "LateAircraftDelay","IsArrDelayed","IsDepDelayed"] column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric" ,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric", "Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum", "Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"] delete_on_done: true check_header: 1 chunk_size: 4194304
請注意,您在配置框中設置的參數已在上述代碼中列出。現在,運行這個單元。一段時間後,解析完成,您將看到以下輸出−

Examining Dataframe
在處理之後,它生成一個數據幀,可以使用以下語句檢查它−
getFrameSummary "allyears2k.hex"
在執行上述語句時,您將看到以下輸出–-;

現在,您的數據可以輸入機器學習算法了。
下一個語句是一個程序注釋,說明我們將使用回歸模型,並指定預設的正則化和lambda值。
Building the Model
接下來是最重要的聲明,那就是構建模型本身。這在下面的語句中有詳細說明;
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}
我們使用廣義線性模型集glm,它是一個具有二項族類型集的廣義線性模型集。您可以在上面的語句中看到這些突出顯示。在我們的例子中,預期的輸出是二進位的,所以我們使用二項式類型。您可以自己檢查其他參數;例如,查看前面指定的alpha和lambda。有關所有參數的說明,請參閱GLM模型文檔。
現在,運行這個語句。在執行時,將生成以下輸出;
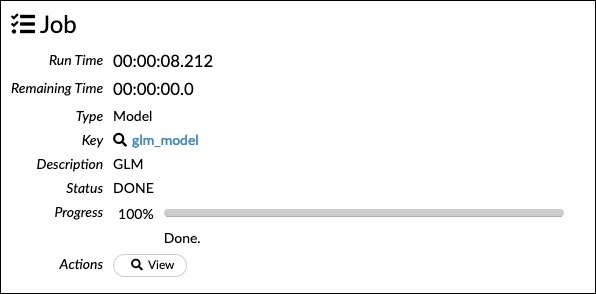
當然,在你的機器上執行的時間是不同的。下面是這個示例代碼中最有趣的部分。
Examining Output
我們只需使用以下語句輸出我們構建的模型−
getModel "glm_model"
注意glm_model是我們在前面的語句中構建模型時指定爲model_ID參數的模型ID。這給了我們一個巨大的輸出,詳細說明了幾個不同參數的結果。報告的部分輸出顯示在下面的螢幕截圖中;

正如您在輸出中看到的,它說這是在數據集上運行廣義線性建模算法的結果。
在記分歷史的上方,您可以看到模型參數標籤,展開它,您將看到構建模型時使用的所有參數的列表。如下截圖所示。

同樣,每個標記提供特定類型的詳細輸出。自己展開各種標籤來研究不同類型的輸出。
Building Another Model
接下來,我們將在我們的數據框架上構建一個深入學習模型。示例代碼中的下一個語句只是一個程序注釋。下面的語句實際上是一個建模命令。如圖所示;
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}
正如您在上面的代碼中看到的,我們指定deeplearning來構建模型,其中幾個參數設置爲deeplearning模型文檔中指定的適當值。當您運行此語句時,它將比GLM模型構建花費更長的時間。模型構建完成後,您將看到以下輸出,儘管計時不同。

Examining Deep Learning Model Output
這將生成輸出類型,可以像前面那樣使用以下語句檢查輸出。
getModel "deeplearning_model"
我們將考慮如下所示的ROC曲線輸出,以供快速參考。

與前面的例子一樣,展開各個選項卡並研究不同的輸出。
Saving the Model
在研究了不同模型的輸出之後,您決定在生產環境中使用其中一個模型。H20允許您將此模型保存爲POJO(普通的舊Java對象)。
在輸出中展開最後一個標記預覽POJO,您將看到用於微調模型的Java代碼。在生產環境中使用此選項。

接下來,我們將學習H2O的一個非常令人興奮的特性,我們將學習如何使用AutoML來測試各種算法,並根據它們的性能對它們進行排名。
H2O - AutoML
要使用AutoML,請啓動一個新的Jupyter筆記本,並按照以下步驟進行操作。
Importing AutoML
首先使用以下兩個語句將H2O和AutoML包導入到項目中;
import h2o from h2o.automl import H2OAutoML
Initialize H2O
Initiatize H2O using the following statement&UNMIN;
h2o.init()
您應該在螢幕上看到集羣信息,如下面的螢幕截圖所示;

Loading Data
我們將使用本教程前面使用的iris.csv數據集。使用以下語句加載數據−
data = h2o.import_file('iris.csv')
Preparing Dataset
我們需要決定特徵和預測列。我們使用與前面案例中相同的特性和謂詞列。使用以下兩個語句設置features和output列−
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] output = 'class'
將數據按80:20的比例分割,用於培訓和測試;
train, test = data.split_frame(ratios=[0.8])
Applying AutoML
現在,我們都準備好在數據集上應用AutoML了。AutoML將在我們設置的固定時間內運行,並給出優化模型。我們使用以下語句設置AutoML−
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)
第一個參數指定要計算和比較的模型數。
第二個參數指定算法運行的時間。
我們現在調用AutoML對象上的train方法,如下所示;
aml.train(x = features, y = output, training_frame = train)
我們將x指定爲前面創建的features數組,將y指定爲輸出變量以指示預測值,將dataframe指定爲train數據集。
運行代碼,您將不得不等待5分鐘(我們將max_runtime_secs設置爲300),直到您得到以下輸出&負;

Printing the Leaderboard
當AutoML處理完成時,它會創建一個排行榜,對它所評估的所有30種算法進行排名。要查看排行榜的前10條記錄,請使用以下代碼−
lb = aml.leaderboard lb.head()
在執行時,上面的代碼將生成以下輸出−
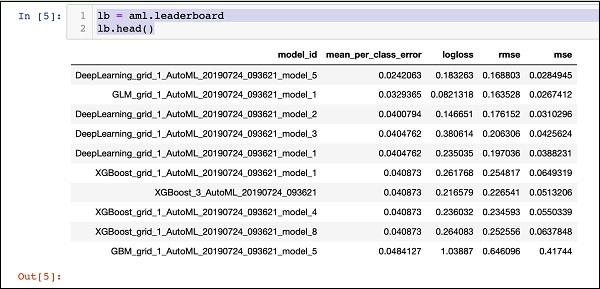
顯然,深度學習算法得到了最大的分數。
Predicting on Test Data
現在,您已經對模型進行了排名,您可以在測試數據中看到最高級別模型的性能。爲此,請運行以下代碼語句−
preds = aml.predict(test)
處理將繼續一段時間,完成後您將看到以下輸出。

Printing Result
使用以下語句列印預測結果−
print (preds)
在執行上述語句時,您將看到以下結果&負;

Printing the Ranking for All
如果要查看所有測試算法的級別,請運行以下代碼語句−
lb.head(rows = lb.nrows)
執行上述語句後,將生成以下輸出(部分顯示)&負;
Conclusion
H2O爲在給定數據集上應用不同的ML算法提供了一個易於使用的開源平台。它提供了一些統計和ML算法,包括深度學習。在測試期間,您可以根據這些算法微調參數。您可以使用命令行或提供的名爲Flow的基於web的界面來執行此操作。H2O還支持AutoML,它提供了基於性能的幾種算法的排名。H2O在大數據方面也表現出色。對於數據科學家來說,將不同的機器學習模型應用到他們的數據集上並選擇最適合他們需求的模型無疑是一個福音。