Flume和Sqoop
在我們了解Flume和Sqoop之前,讓我們研究數據加載到Hadoop的問題:
使用Hadoop分析處理數據,需要裝載大量從不同來源的數據到Hadoop集群。
從不同來源大容量的數據加載到Hadoop,然後這個過程處理它,這具有一定的挑戰。
維護和確保數據的一致性,並確保資源的有效利用,選擇正確的方法進行數據加載前有一些因素是要考慮的。
主要問題:
1. 使用腳本加載數據
傳統的使用腳本加載數據的方法,不適合於大容量數據加載到 Hadoop;這種方法效率低且非常耗時。
2. 通過 Map-Reduce 應用程序直接訪問外部數據
提供了直接訪問駐留在外部係統中的數據(不加載到Hadopp)到map reduce,這些應用程序複雜性。所以,這種方法是不可行的。
3.除了具有龐大的數據的工作能力,Hadoop可以在幾種不同形式的數據上工作。這樣,裝載此類異構數據到Hadoop,不同的工具已經被開發。Sqoop和Flume 就是這樣的數據加載工具。
SQOOP介紹
Apache Sqoop(SQL到Hadoop)被設計為支持批量從結構化數據存儲導入數據到HDFS,如關係數據庫,企業級數據倉庫和NoSQL係統。Sqoop是基於一個連接器體係結構,它支持插件來提供連接到新的外部係統。
一個Sqoop 使用的例子是,一個企業運行在夜間使用 Sqoop 導入當天的生產負荷交易的RDBMS 數據到 Hive 數據倉庫作進一步分析。
Sqoop 連接器
現有數據庫管理係統的設計充分考慮了SQL標準。但是,每個不同的 DBMS 方言化到某種程度。因此,這種差異帶來的挑戰,當涉及到整個係統的數據傳輸。Sqoop連接器就是用來解決這些挑戰的組件。
Sqoop和外部存儲係統之間的數據傳輸在 Sqoop 連接器的幫助下使得有可能。
Sqoop 連接器與各種流行的關係型數據庫,包括:MySQL, PostgreSQL, Oracle, SQL Server 和 DB2 工作。每個這些連接器知道如何與它的相關聯的數據庫管理係統進行交互。 還有用於連接到支持Java JDBC協議的任何數據庫的通用JDBC連接器。 此外,Sqoop提供優化MySQL和PostgreSQL連接器使用數據庫特定的API,以有效地執行批量傳輸。
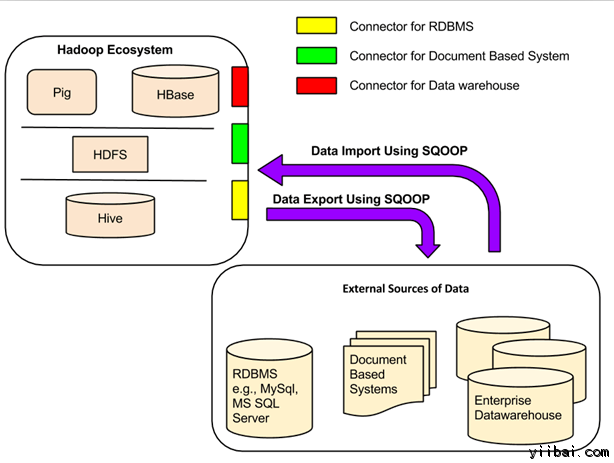

除了這一點,Sqoop具有各種第三方連接器用於數據存儲,
從企業數據倉庫(包括Netezza公司,Teradata和甲骨文)到 NoSQL存儲(如Couchbase)。但是,這些連接器冇有配備Sqoop束; 這些需要單獨下載並很容易地安裝添加到現有的Sqoop。
FLUME 介紹
Apache Flume 用於移動大規模批量流數據到 HDFS 係統。從Web服務器收集當前日誌文件數據到HDFS聚集用於分析,一個常見的用例是Flume。
Flume 支持多種來源,如:
-
“tail”(從本地文件,該文件的管道數據和通過Flume寫入 HDFS,類似於Unix命令“tail”)
-
係統日誌
-
Apache log4j (允許Java應用程序通過Flume事件寫入到HDFS文件)。
在 Flume 的數據流
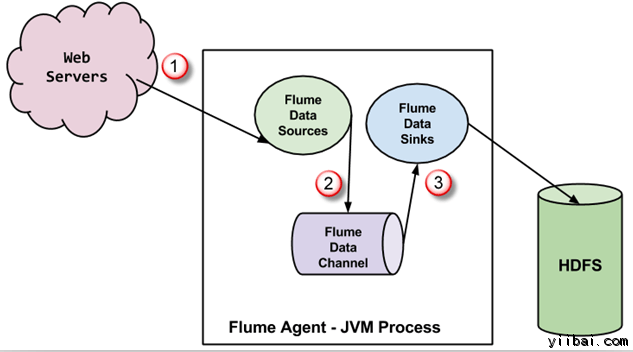
Flume代理是JVM進程,裡麵有3個組成部分 - Flume Source, Flume Channel 和 Flume Sink -通過該事件傳播發起在外部源之後。

-
在上麵的圖中,由外部源(Web服務器)生成的事件是由Flume數據源消耗。 外部源將事件以目標源識彆的格式發送給 Flume 源。
-
Flume 源接收到一個事件,並將其存儲到一個或多個信道。信道充當存儲事件,直到它由 flume消耗。此信道可能使用本地文件係統以便存儲這些事件。
-
Flume 將刪除信道,並存儲事件到如HDFS外部存儲庫。可能會有多個 flume 代理,在這種情況下,flume將事件轉發到下一個flume代理。
FLUME 一些重要特性
-
Flume 基於流媒體數據流靈活的設計。這是容錯和強大的多故障切換和恢複機製。 Flume 有不同程度的可靠性,提供包括“儘力傳輸'和'端至端輸送'。儘力而為的傳輸不會容忍任何 Flume 節點故障,而“終端到終端的傳遞”模式,保證傳遞在多個節點出現故障的情況。
-
Flume 承載源和接收之間的數據。這種數據收集可以被預定或是事件驅動。Flume有它自己的查詢處理引擎,這使得在轉化每批新數據移動之前它能夠到預定接收器。
-
可能 Flume 包括HDFS和HBase。Flume 也可以用來輸送事件數據,包括但不限於網絡的業務數據,也可以是通過社交媒體網站和電子郵件消息所產生的數據。
自2012年7月Flume 發布了新版本 Flume NG(新一代),因為它和原來的版本有明顯的不同,因為被稱為 Flume OG (原代)。

